くずし字コンペ:CenterNetについて考察してみました
この記事はKaggle アドベントカレンダー 2019の7日目の記事です。
幅野です。
くずし字コンペの上位解法として利用されていた物体検出モデルの一つであるCenterNetについて紹介・考察をしていきます。
今回紹介するCenterNetは「Object As Points」で提案されているモデルです。
「CenterNet: Keypoint Triplets for Object Detection」で提案されているCenterNetは下記で弊社の技術ブログとして紹介しているので良かった見てみてください。
最後にCenterNetのStackingのアイデアについて紹介できればと思います。
背景:くずし字コンペ
くずし字コンペは文書画像からくずし字の種類と位置を推定するコンペです。
https://www.kaggle.com/c/kuzushiji-recognition
物体検出タスクの中ではPASCAL VOC Datasetと比較すると物体のカテゴリ数と1つの画像の中で推定したい物体の数が多いタスクでした。
画像枚数が少なく画像コンペにしてはリソース的に参加の敷居が低そうなコンペの印象がありましたが、このコンペはメダル付与が与えられないことからコンペの参加をしなかった人も多かったかもしれません。
自分もこのコンペを積極的に参加はできなかったのですが、カーネルや上位解法を見るだけでもかなり勉強になりました。
そして今後の上位解法として可能性のあるCenterNetが多く使われていたコンペでもあるので今回はCenterNetについて、その応用方法とアイデアを紹介できればと思います。
またモデルや学習方法についての数式による厳密な解説などは今回の記事では説明しないのでご了承ください。
物体検出タスクで利用されてきたモデル
物体検出は画像から物体の種類と位置を推定するタスクです。
くずし字コンペ以前にも多くの物体検出タスクのコンペが開催されています。
最近だとOpen Images 2019 - Object Detectionなどですね。
この物体検出タスクには2-stage, 1-stageのモデルに分類されて研究されています。
詳細なアーキテクチャの説明は省略しますが、いくつか紹介したいと思います。
2-stageモデル:R-CNN
2-stageモデルは物体のカテゴリを推定するモデルと物体の位置を推定するモデルを2つ利用して物体検出を行います。
モデルはFaster R-CNN, Mask R-CNNなどです。
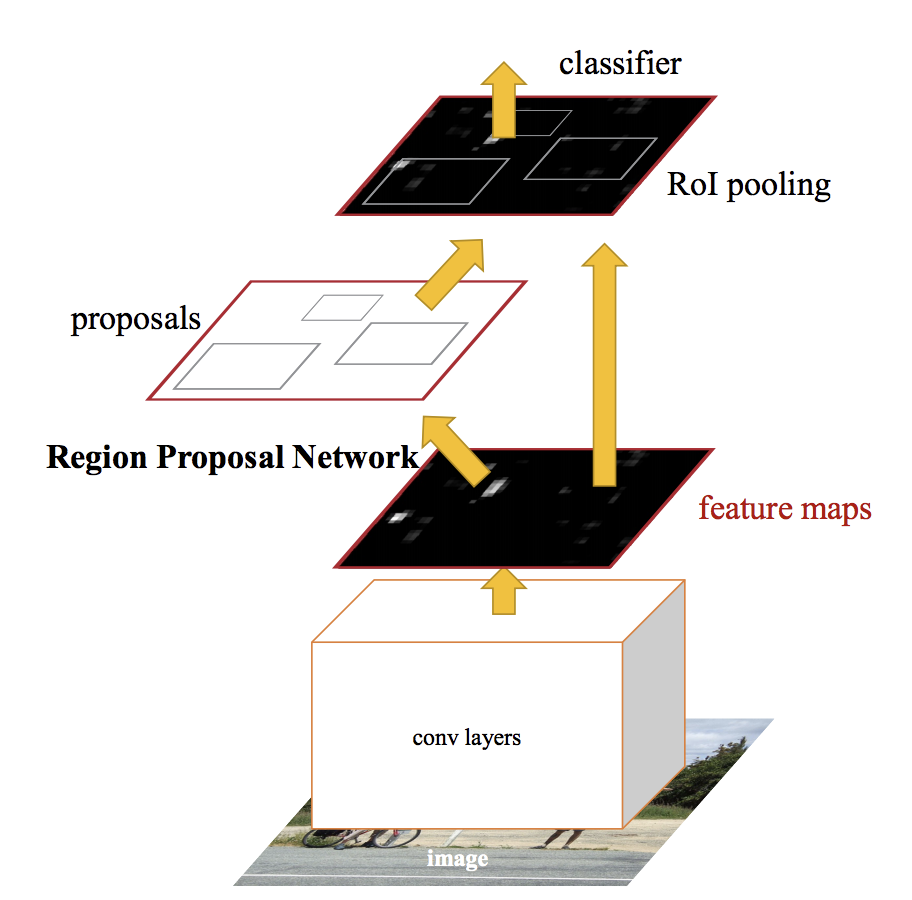
参考:https://arxiv.org/abs/1506.01497
Mask R-CNNは物体検出以外にも物体の領域をピクセルレベルで推定するInstance Segmentationにも利用されています。
2-stageモデルは1-stageモデルと比較すると精度が高く、Kaggleの物体検出コンペでも上位解法で利用されています。
今回のくずし字コンペの1位解法ではCascade R-CNNが利用されていました。
ただ、2-stageモデルは2つのモデルを利用して物体検出を行うため、推論速度が1-stageモデルと比較すると遅い傾向にあります。
実際のシステムにおいて推論速度、モデルサイズの制約がある場合には2-stageモデルを利用できないケースがあるかもしれません。
そのときに利用されることが多いのが1-stageモデルです。
1-stageモデル:SSD YOLO
1-stageモデルは1つのモデルで物体の種類と位置を推定します。
Single Shot Detector(SSD), You Look Only Once(YOLO)などのモデルが提案されています。
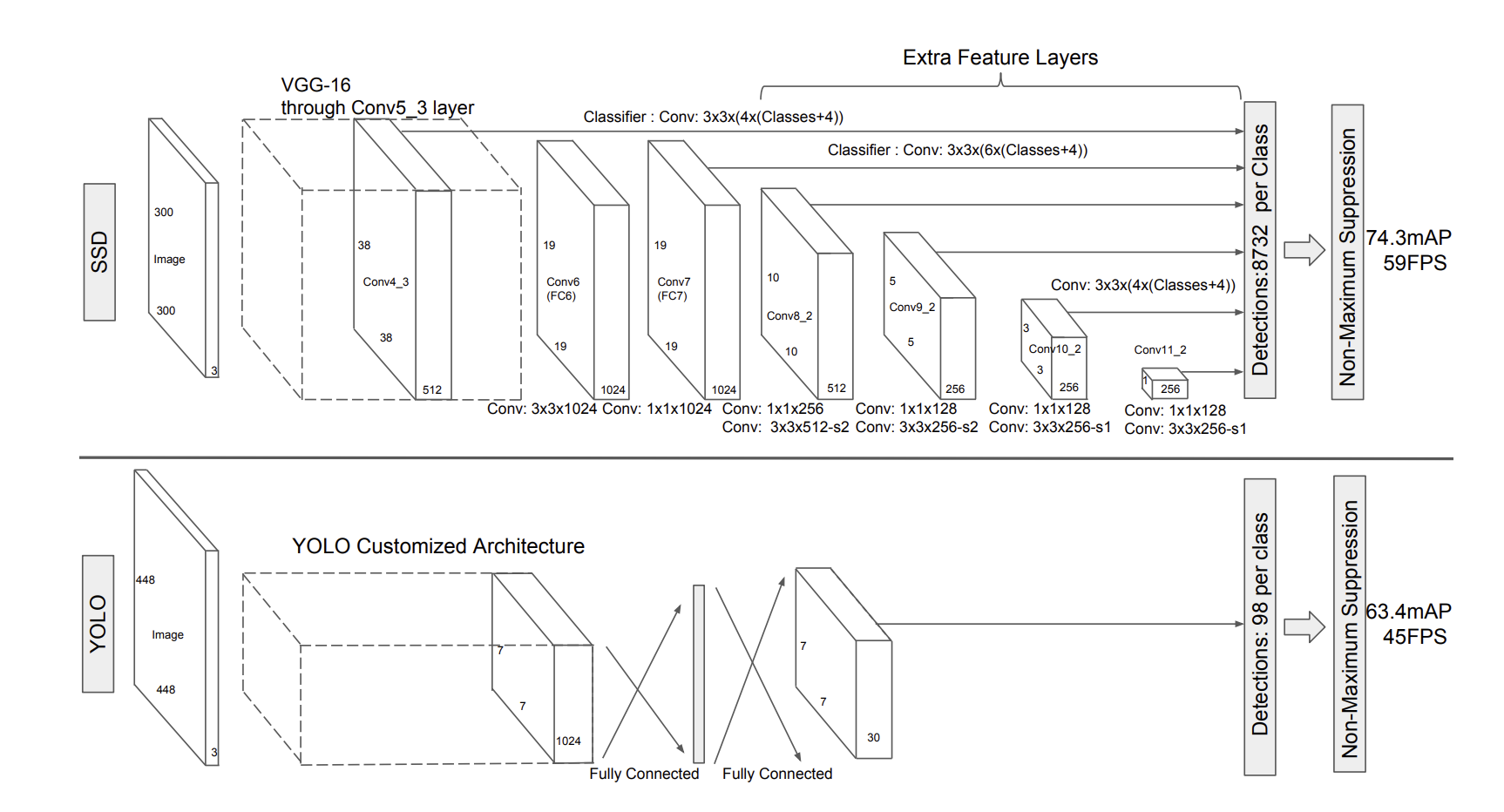
参考:https://arxiv.org/abs/1512.02325
1つのモデルで推定するということから推論速度が2-stageモデルと比較すると速いのが特徴です。
ただ、先程いったように物体検出の精度(IOUなど)を競うKaggleでは1-stageモデル単体で上位解法に上がってくることはあまりありませんでした。
しかし、2019年4月に出た論文「Object As Points」でYOLOv3などよりも推論速度が速く、精度もよいCenterNetが提案されました。
このCenterNetは2-stageモデルがあるなか、くずし字コンペの5位解法で利用されています。
CenterNet(Object As Points)
今までのSSD, YOLOなどの1-stageモデルではモデルで複数の領域候補を推定したあとNon-Maximum-Supression(NMS)を利用して複数の領域候補を1つにまとめて最終的にBoudingBoxを出力していました。
しかし、このNMSは微分計算ができないことからEnd-to-Endで学習することができませんでした。
そこでBoundingBoxの中心をキーポイントとしてヒートマップを出力することでNMSをしなくてもBoundingBoxを出力できるようにしたのがCenterNetです。
また、このキーポイント系の検出モデルはCenterNet以前からCornerNetなどが提案されていました。
CornerNetに関しては以前弊社の技術ブログでまとめました。
ただ、CornerNetは物体の左上と右上のキーポイント2つを出力するので、キーポイントをグルーピングする必要がありました。
Object As Pointsで提案されているCenterNetはキーポイントは物体の中心のみにし、それに付随してカテゴリやBounding Boxを推定するアーキテクチャとなっているので非常にシンプルです。
また、カテゴリだけでなくdepthを出力することで3次元の物体検出に拡張したり、中心点からの関節点を出力するモデルにすることによって、姿勢推定へ適応できたりします。
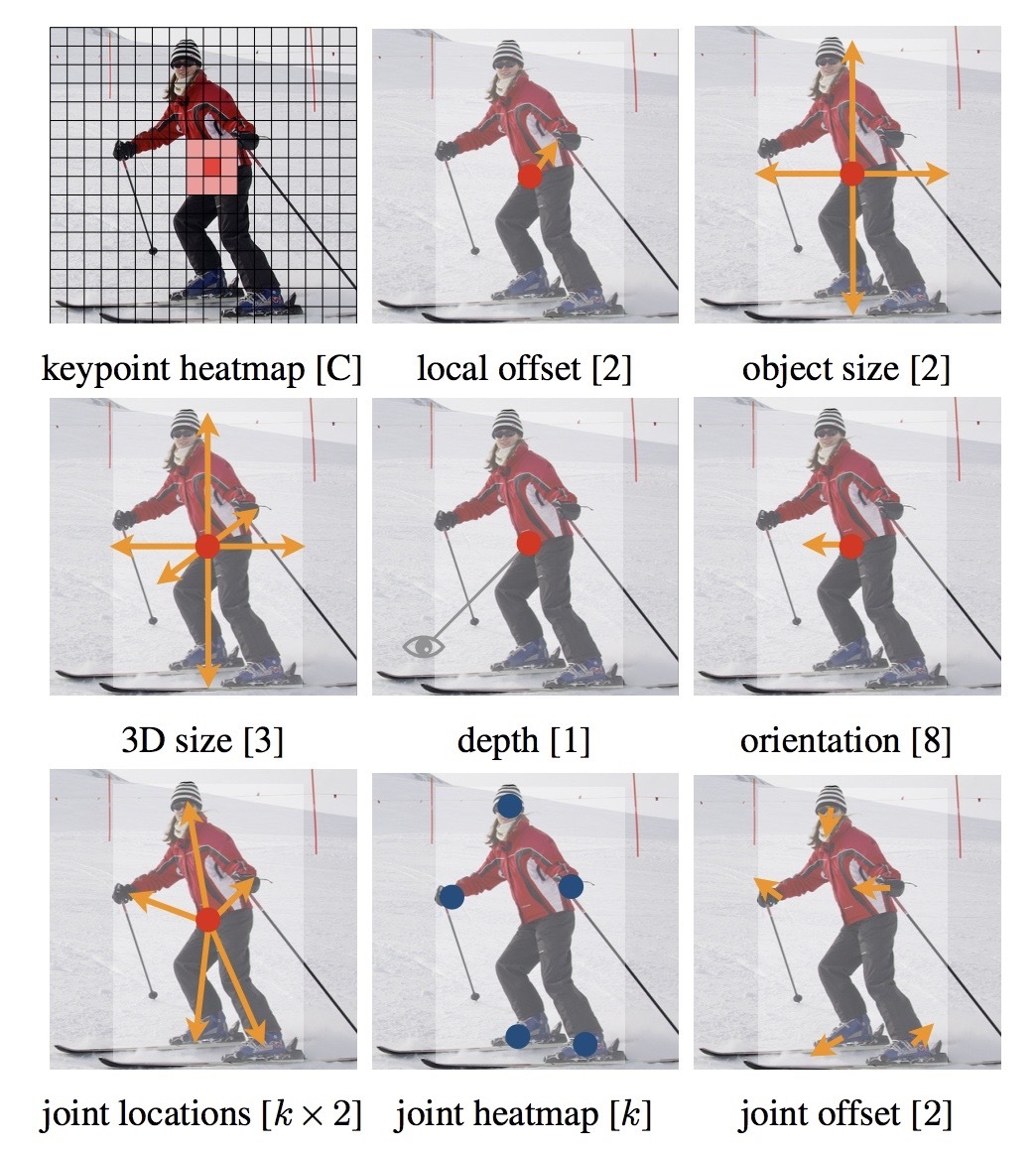
このように物体検出を様々な用途に拡張してモデルを構築できるのもCenterNetの特徴の一つです。
くずし字コンペにおけるCenterNetの利用方法
くずし字コンペでは7位・5位の方が解法としてCenterNetが利用しています。
7位の方はCenterNetに関するカーネルを投稿しています。非常に参考にさせていただきました。
https://www.kaggle.com/kmat2019/centernet-keypoint-detector
7位の方の解法は2-stageのなかの文字を検出するモデルとしてCenterNetを利用しており、5位の方はCenterNetのみを利用して文字の位置の推定・文字の種類の推定も行っています。
より詳細な解法についてはそれぞれのSolutionとして掲載されています。
https://www.kaggle.com/c/kuzushiji-recognition/discussion/112899
https://www.kaggle.com/c/kuzushiji-recognition/discussion/112771
アイデア:CenterNetのRefine
コンペ終了後に上位解法などを通して色々勉強させていただいたということもあり、CernterNetを利用してLate Submissionしようと思っていました。
このアドベントカレンダーに向けて学習を回していたのですが、現在学習中で評価を出せていないということもあり、ひとまずアイデアを紹介させていただければと思います。。。
当然今回紹介するアイデアが必ず良い結果が出るとは限りませんが、今後良い結果を投稿できればと思っています。
1stageモデルとして利点のあるCenterNetですが、Stackingのような方法を利用してヒートマップをより精度の高いものへRefineできないか考えてみました。
以下のようにStackingすることを考えます。

通常のstackingとほぼ同じように思えますが、この発想はOpenPoseなどの姿勢推定モデルのベースとなったPose Estimation Machineから着想を得ました。
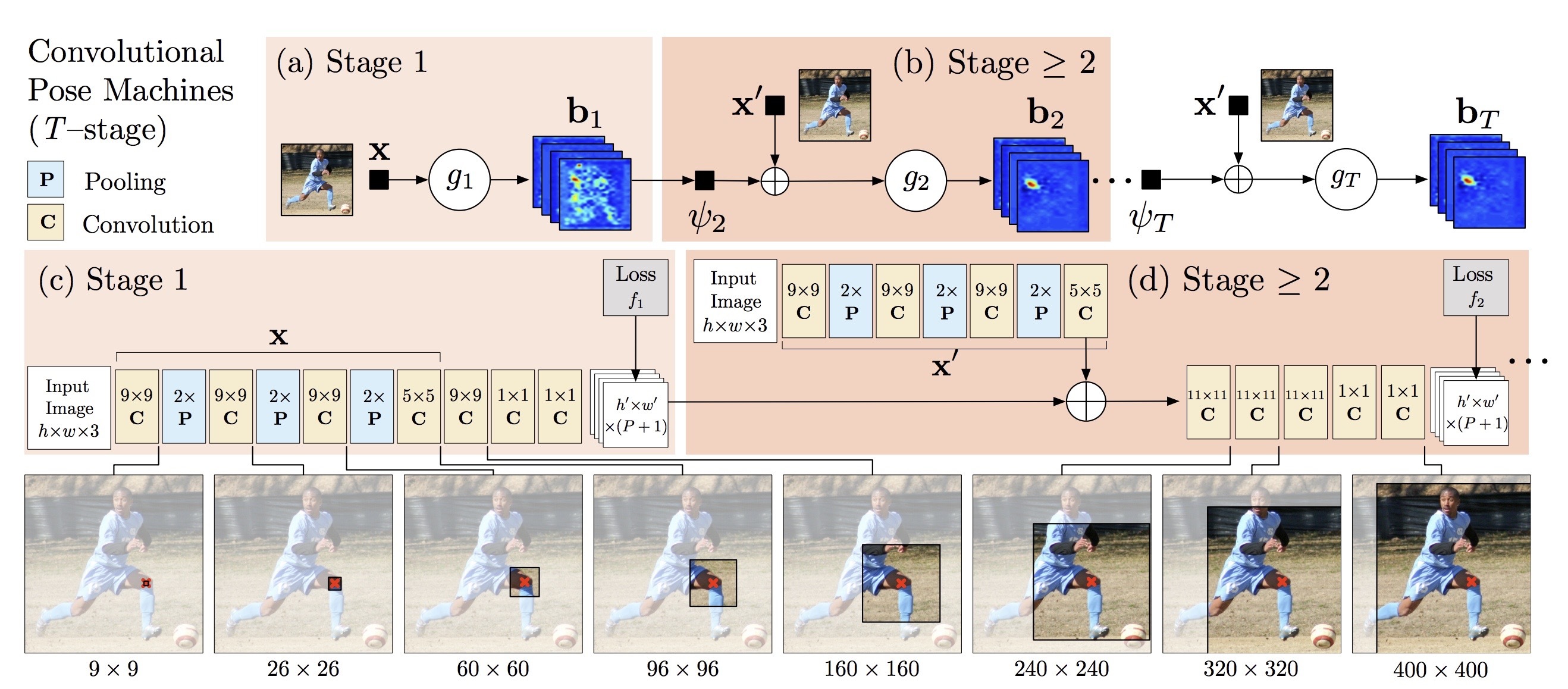
参考:https://arxiv.org/abs/1602.00134
Convolutional Pose Machineでは画像から各関節のヒートマップを出力するのですが、互いの関節の位置は他の関節の位置を推定するのに寄与するという仮説を建てて、ヒートマップをRefineしていくようなモデルアーキテクチャとなっています。
くずし字でも文章として文字が整列していることもあり、他の文字との位置関係はうまく利用できると思いました。実際に5位の解法ではConvolution Pose Machineと似ているFPNアーキテクチャを利用しています。
ただ、出力チャンネル数はConvolution Pose Machineのように統一してはおらず、各Stageの出力に対して損失関数をかけているわけでもなさそうです。
なので、こちらをStackingのようにCenterNetを積み重ねることによってより精度の高いヒートマップを出力できるのではないかと考えています。
感想
CenterNetは1-stage&色々なタスクに応用しやすいということで、今後様々な部分で応用、改良されていくと思っています。
今後、画像系のコンペが出たらぜひCenterNetを一つのモデルとして利用できたらと思っています。
物体検出のデータ生成手法を提案した論文「SNIPER: Efficient Multi-Scale Training」を読んでみました
インターンの中村です。
今回はSNIPERという論文を読みました。
訓練手法を提案した、プラクティカルな論文。そのため、難解な数学はあまりなく、直観的な説明がおおかった。
multi-scale訓練時に画像の一部をいい感じにサンプリングして、解像度を下げておくことによって、単GPUでも20images/batchで訓練できるようになり、batch normalizationの恩恵を受けられるようにしたというメリットがある。
概要

難しい物体検出タスクは、高い解像度で画像全体に対して訓練するのが良いとされていた。しかし、これを処理するのは計算量が大きく、特に常人のGPUではバッチ数を増やすのがほぼ不可能だった。
そこで、画像の一部を切り取り、512x512にリサイズして、それを食わせて訓練するようにした。このリサイズされた箱をchipと呼ぶ。
難しい物体検出タスクは、高い解像度で画像全体に対して訓練するのが良いとされていた。しかし、これを処理するのは計算量が大きく、特に常人のGPUではバッチ数を増やすのがほぼ不可能だった。
そこで、画像の一部を切り取り、512x512にリサイズして、それを食わせて訓練するようにした。このリサイズされた箱をchipと呼ぶ。
仕組み
positive chip生成
* いくつかのスケール$s_1, \ldots ,s_n$に対して、画像を$(W_i, H_i)$にリサイズし、$K\times K$ pixelのchipを$d=32$ pixelずらしながら、chipの候補を作る。
* それぞれのスケールに対して、どのGTが含まれるかを決める
* GTの面積が$\mathcal{R}^i =\left[ r_{min}^i, r_{max}^i \right]$に入っていれば、GTはスケールに対してvalidとよばれる。そのようなGTを$\mathcal{G}^i$とする
* $\mathcal{G}^i$がすべていずれかのchipにカバーされるように貪欲法でchipを選ぶ
* 「カバーされている」とは完全に箱が含まれているということ
* 選ばれたchipの集合を$\mathcal{C^i_{pos}}$と呼ぶ。
* chip内に(意図せず)一部が含まれてしまったGTはcropされていると呼ぶ。これも正解データとして含めるが、カバーされている判定にはならない
こうすることで、すべてのGTが適切なスケールのチップに必ず含まれているようにできる。チップの解像度は画像自体より非常に小さい(画像が高解像度ならば、一番小さいもので10x以上)ので、ほとんどの背景を高解像度状態で処理することはない
補足
- 同じGTが複数のchipに含まれることがある
- $\mathcal{R}^i, \mathcal{R}^{i+1}$にはカブっている部分があるので、おなじGTが$\mathcal{G}^i, \mathcal{G}^{i+1}$両方に含まれることがある
negative chip生成
- これだけだと、背景が使われないので、False Positiveに非常に弱くなってしまう
- アトランダムに選ぶのでは、easy sample(簡単に背景とわかるもの)ばかりになってしまう なので、次のようにする。
- RPNを数epochs適当に訓練する。この時negative chipは使わない。
- 当然、false positiveに弱くなる=FPをたくさん検出してしまう。だがそれでいい
- このRPNを全訓練データに適用、Proposalのリストを得る
- このうち$\mathcal{C^i_{pos}}$にカバーされているものは本物の可能性が高いので除く。そうでないものは「Positiveっぽさがあるが実際にはそうではない部分」
- $\mathcal{R}^i$のなかで$M$個以上のproposalを含むようなchipをあつめ、$C^i_{neg}$とする。これを保存(プール)しておく
- 実際の訓練では$\cup\ ^n _{i=1} C^i_{neg}$のプールからも何個か取り出すようにする

訓練時のラベリング
訓練時は、chipに含まれている すべての GTで訓練する。すなわち、GTがchipの$\mathcal{R}$に入っていなくても訓練に使う。
- 例えば、小さいchipに巨大な物体の一部がクロップされて入っていたら、それに対する検出結果も使いたいので
メリット
訓練時には、データセット全体からランダムにchipをサンプルする。scaleは$(512/ms, 1.667, 3)$(ただし、$ms=\max(width, height)$)
- 画像の短辺が512より小さい場合は、ゼロパディングする
平均して512x512のchipsを5個程度生成。
計算量は多そうに見えるが、上述のように画像の一部を、それも縮小した状態で訓練するので、pixel数ベースでの計算量は単純に全体を処理するときに比べ30%増加ですむ(COCOの場合。COCOは画像サイズが800x1333)。
実際には、画像サイズが同じになっているので、データがより良い感じに処理でき、30%の増加は簡単にひっくり返る。 まとめると、multi-scaleな訓練、大きなバッチサイズ、batch normalizationの恩恵を計算が遅くなることなしに8GPUで受けられるようになった。 これまで、高解像度のまま処理することが物体検出のタスクには必要と考えられてきた - そのときバッチ数を増やすために必要だったマルチGPU法も、遅かったりといろいろ問題があった
しかし、提案手法がうまく行ったことから、negative sampleと巨大サンプルが適切に含まれていれば、COCOのような難しいデータセットに対しても訓練可能ということが示された。ある程度の視野より広い範囲のコンテキスト情報は不要か。
実験の詳細
- COCOデータセット
- $\mathcal{R} = (0, 80^2), (32^2, 150^2), (120^2, \inf)$
- 6 epochs訓練, 1 epoch = 11000 iterations
- FP用RPNは2 epochs訓練、1 epoch = 7000 iterations
- よって、RPNの訓練は全訓練時間の20%以下。嬉しいポイント
- 他にも、mixed precision trainingなど、訓練のコツが色々細かく書かれていたので興味のある人は論文を読んでほしい
結果

- ARは$C^i_{neg}$を使うか否かとは関係がなかった
- RecallはFPの量とは関係がないためと思われる

- 一方で、APにはもちろん効果がある
- スケールを減らす1と性能が大きく下がる→multi-scalingは訓練に効果的ということがわかる

- 効率的なバッチ推論パイプラインによりV100 GPUで5 image/sec 処理できた
- 性能も、特にMobilenetv2で大きく向上した
-
$(512/ms, 1.667)$ に減らした↩
DNNにおける蒸留を提案「Distilling the Knowledge in a Neural Network」を読みました
CTOの幅野です。
今回はDNNにおいてはじめて提案された蒸留手法の論文について解説していきます。
蒸留のモチベーション
1. 背景
DeepLearningモデルは層が深く、パラメータが多くすることでモデルの表現力を高め精度を向上させやすくなることが知られています。 さらにモデルを複数作成し、複数モデルの出力を利用して予測をすることで精度を向上させるアンサンブル方法も提案されています。 しかし、複数のニューラルネットワークを運用することは処理速度が遅くなったり、マシンリソースが多く必要だったりとあまり、現実的ではないです。 なので、Singleモデルでアンサンブルモデルや巨大なモデルと同等の表現力を持たせることが必要です。
2. 蒸留の方法
蒸留とは大きなモデルやアンサンブルモデルなどの教師モデルの出力結果を元に1つのモデルを学習する方法です。学習させるモデルを生徒モデル、生徒モデルを学習するときに使うモデルを教師モデルと呼びます。
具体的には2つの損失関数で生徒モデルを学習します。
- Hard Target: 用意した教師データとの損失関数
- Soft Target: 教師モデルの出力結果との損失関数
蒸留を利用することで、生徒モデルは通常の学習をしたときよりも高い精度を出すことができます。
3. 教師モデルの出力を学習すること
生徒モデルは教師モデルの出力結果を学習することによって教師モデルの出力の確率分布を学習することができます。 クラス分類タスクにおける教師データは該当するクラスの値を1とし、それ以外を0として学習を行います。 しかし教師モデルの全ての出力は教師データのようなスパースなベクトルにはなりません。 MNISTの分類を例にすると、「2」の画像が与えられたときに「2」クラスの確率が高くなることが求められますが、画像として似ている「7」クラスも同時に確率がある程度あるかもしれません。 このように正解クラス以外のクラスの出力確率を利用する、つまり教師モデルの出力確率分布を学習します。
学習方法
本手法ではSoft Targetをクロスエントロピー誤差で学習することを考えます。
Soft Targetを蒸留に利用する理由は教師モデルの確率分布をより学習しやすくするためにHard Targetより多くの情報量を提供することです。
蒸留をする際に、パラメータ$T$をSoftMax関数に導入しています。
$$
q_{i}=\frac{\exp \left(z_{i} / T\right)}{\sum_{j} \exp \left(z_{j} / T\right)}
$$
$q$は生徒モデルのクラス$i$の確率を表しており、$z_i$はSoftMax関数を適応する直前のニューラルネットワークの出力です。教師モデルにもこのSoftMax関数を導入します。通常のSoftMax関数では$T=1$ですが、$T$の値を上げることで$q$の確率分布を滑らかにすることができます。逆に$T$の値を下げることによって、クラス間の確率の差が大きくなります。
確率分布を滑らかにできるというのは本来低かった確率のクラスが大きくなっています。
これにより、正解クラス以外のクラスの確率を大きくすることができ、教師モデルに反映しやすくすることができます。
Soft Targetでは教師モデルの確率分布を学習したいのでその確率分布をどこまで学習するかを$T$によって調整することができます。
評価
ARSタスクの精度比較
Automatic Speech Recognition (ASR)における2000hほどの英語のspeaking datasetで検証しています。 タスクは各フレームの音声データを元に事前にHMMでクラスタリングした14000種類のクラスを予測する問題です。 Base Lineはhard targetのみのSingleモデルで、10xEnsembleは10個のアンサンブルモデルです。 Deistilled Single modelはHard Targetと10個のアンサンブルモデルの出力結果を元にしたSoft Targetの誤差をそれぞれ0.5に重み付けした値の和をLossとして学習したものです。$T=20$で学習をしています。
ネットワークは全て同じ構造です。 蒸留手法がBaseLineより高くWord Error Rate(WER)ではアンサンブルとほぼ同等の精度を出しています。

またSoft TargetはHard Targetより学習に役立つ情報を持っていると考えており、それらの情報は小さいデータセットでの学習に対しても寄与すると主張しています。 ASRでデータセットを減らして精度評価をしています。
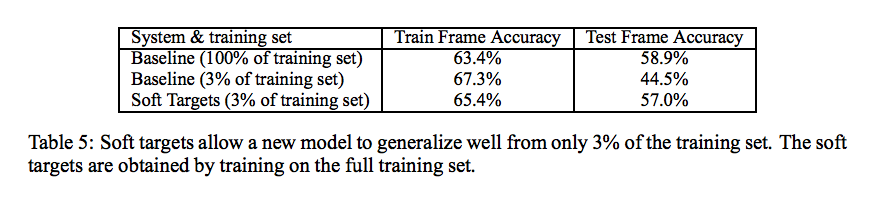
Soft Targetsを利用することでテストデータでは3%Baselineより高い精度を出しています。 これらのことから小さいデータに対しても寄与する→正則化がかかっていることがわかります。
JFTデータセットでの検証
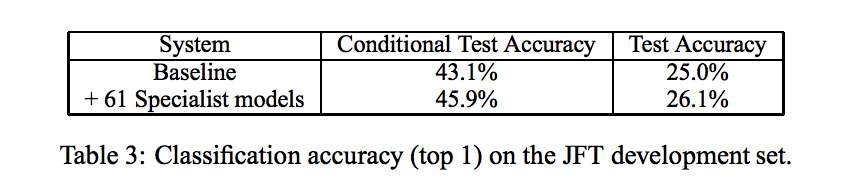
JFTデータセットはGoogleが用意した1億の画像を15000クラス割り当てられているデータセットです。 このようなデータセットで精度を上げるためにアンサンブルを使おうと考えると、全てのデータセットを使って複数モデルを学習することは計算量が膨大になり現実的ではありません。 そこで本手法の蒸留方法を利用したアンサンブルモデルの作成方法を利用して評価しています。
具体的にはデータセットを$k$個に分割して、それぞれのデータセットでSpetialistモデルを学習し、Spetialistモデルでアンサンブルを行います。
Spetialistモデルの作成手順は以下の通りです。
- 全てのデータセットで作成したモデルを1つ学習する(Generalist Model)
- Generalist Modelの出力結果を元に計算したクラスのConfusion Matrixからクラスタリングしてデータを分割
- Generalist Modelと分割したデータを利用して学習
Generalist Model
最初に全てのデータセットでGeneralist Modelを学習します。Generalist ModelがSpetialistモデルを学習するときの教師モデルとなります。
クラスタリングによるデータ分割
クラスのクラスタリングはK-Meansを利用してクラスタリングをしています。
クラスタリング例は以下のようになっています。

このクラスタリングによってデータセットを分割して、分割したデータセットそれぞれでSpetialist Modelを学習します。分割したデータセットを
とします。
Generalistモデルと分割したデータによるSpetialist Modelの作成
からGeneralist Modelを利用してSpetialist Modelを作成します。
まず最初にデータに対してGeneralist Modelで予測をし、最も確率の高かったクラスを
とします。
この
が
クラスのグループの中に入っているデータを抽出します。
抽出したデータを
とします。
このを元にGeneralist ModelとSpetialist modelを学習します。
そのときに利用する損失関数は以下です。
$$
K L\left(\mathbf{p}^{g}, \mathbf{q}\right)+\sum_{m \in A_{k}} K L\left(\mathbf{p}^{m}, \mathbf{q}\right)
$$
はGeneralist Modelの予測確率で
は
としたGeneralist Modelの予測確率です。
は
に対して推論したSpetialist Model
の予測確率を表しています。
これによりSpeticalist Modelを61個作成した結果が以下のようになります。
MobileNet論文その3: 「Searching for MobilenetV3」を読んでみました
インターンの中村です。
今回はMobileNetV3を読みました。
論文の要旨
正式なタイトルは"Searching for MobileNetV3"。
タイトル通り、かっこいい新手法の提案というよりは、機械的な探索などを地道に貪欲に取り入れ、MobileNetV2の性能を向上させる方法を探したというのが主な内容。
(GPUではなく)モバイルデバイスのCPU上で速く走らせるために、細かく層の形とかを調整して少しでもMulAddの数を減らそうと試みる。
この結果として、MobileNetV3-Small, MobileNetV3-Largeという2つのモデルを提案している。
というわけで、4つに分けて改良ポイントを述べていく。自動アーキテクチャ探索、効率的な非線形関数、効率的なネットワークデザイン、効率的なセグメンテーションデコーダだ。
自動アーキテクチャ探索
MobileNetV3に使われた自動アーキテクチャ探索(いわゆるNAS, Neural Architecture Search)は主に2つのステップからなる。
まず、MnasNet論文で提案されたplatform-aware NASを使っておおまかにCNNの形を決定する。
つぎに、NetAdaptを使って細かく性能を向上させていく。以上。
platform-aware NASって何
アイデアは単純で、目的関数を定め、それを報酬として受け取る強化学習アルゴリズムを回す。
具体的にはRNNを使って予測し、Proximal Policy OptimizationというアルゴリズムでRNNのパラメータを更新していくらしい(知らない)
 * なお、強化学習を使ったのは便利で報酬がカスタマイズしやすかったため。他のアルゴリズム、たとえば遺伝的アルゴリズムを使っても良いかも by 論文
* 遅延時間計測には実際にGoogle Pixelをつかった。だからplatform-aware
* なお、強化学習を使ったのは便利で報酬がカスタマイズしやすかったため。他のアルゴリズム、たとえば遺伝的アルゴリズムを使っても良いかも by 論文
* 遅延時間計測には実際にGoogle Pixelをつかった。だからplatform-aware
目的関数
モデル$m$が与えられた時、$ACC(m)$を最大化しつつ、実行(遅延)時間$LAT(m)$は小さくしたい。簡単に思いつくのは
$$
\underset{m}{\mathrm{maximize}}\ ACC(m)
$$
$$
\mathrm{subject\ to}\ LAT(m)\leq T
$$
だが、これだと一度の探索で一つの$T$に対するモデルしかできない。NASはコストがかかるので、一度の探索で複数のモデルを見つけたい。なのでこうする:
$$
\begin{eqnarray}
\underset{m}{\mathrm{maximize}}\ &R(m)\\\
=\underset{m}{\mathrm{maximize}}\ &ACC(m)\times {\left[\frac{LAT(m)}{T}\right]}^w
\end{eqnarray}
$$
ただし、$w$は以下で定義される重み係数
$$
w = \begin{cases}
\alpha,\ \mathrm{if}\ LAT(m)\leq T\\\
\beta,\ \mathrm{otherwise}
\end{cases}
$$
とする。
 こうすると、"$T$をちょっとオーバーするけど$ACC$は高い"というモデルとかも提案されるようになる
こうすると、"$T$をちょっとオーバーするけど$ACC$は高い"というモデルとかも提案されるようになる
 本論文における違いとしては、$w=-0.07\rightarrow-0.15$に変更したこと。モデルが小さいときにはLATよりACCが劇的に変わるので、それに対応した
本論文における違いとしては、$w=-0.07\rightarrow-0.15$に変更したこと。モデルが小さいときにはLATよりACCが劇的に変わるので、それに対応した
また、Largeについては、MnasNet-A1と大体一緒だったので、これは省略してNetAdaptのみ行った
どのようにしてモデルを調整したかは、以下の図が詳しい:
 また、パラメータは次の文章の通り:
また、パラメータは次の文章の通り:
 Squeeze-and-Excitationって何????
Squeeze-and-Excitationって何????
Squeeze-and-Excitationって何
以前に別の論文で提案されていた手法。
こちらも仕組みは単純。
 なんらかのコンボリューションブロック$\mathbf{F}$が終わったら、その出力$\mathbf{U}$を
なんらかのコンボリューションブロック$\mathbf{F}$が終わったら、その出力$\mathbf{U}$を
1. Global average poolingする
2. 全結合層にかける(1x1 convのようにチャンネルごとに混ぜ合わせる働きを持つことに注目)$$
s = \mathbf{F}_{ex}(z, \mathbf{W})=\sigma(\mathbf{W}_2\mathrm{ReLU}(\mathbf{W}_1z))
$$
3. $s \in [0, 1]$を「倍率」として扱い、もとの特徴量にチャンネルごとに掛ける
というもの。これだけで性能が向上する
これをSqueeze-and-Exciation Block略してSE Blockという。
 どのチャンネルがよく活性化しているか、という特徴を、チャンネルの重みとして活用しており、軽量なself-attentionのようなものと捉えることができる。
ただ、闇雲に全部の層に突っ込みまくればいいというわけでもなさそうというのも指摘されていた:
どのチャンネルがよく活性化しているか、という特徴を、チャンネルの重みとして活用しており、軽量なself-attentionのようなものと捉えることができる。
ただ、闇雲に全部の層に突っ込みまくればいいというわけでもなさそうというのも指摘されていた:
 中くらいの層では効果があるが、最初の方と最後の方の層ではクラス間にあまり差がない。とくに、最後の方の層はチャネル数が多いのでSE Blockの計算量も大きくなってしまう。
中くらいの層では効果があるが、最初の方と最後の方の層ではクラス間にあまり差がない。とくに、最後の方の層はチャネル数が多いのでSE Blockの計算量も大きくなってしまう。
最終層を取り除くと、ほぼ性能低下なし(<0.1%)でパラメータ増加を10%→4%に落とせる、うれしい!ということも指摘されていた
だが、どの層でSE Blockを使うかというのはハイパラとして細かく調整できそうだ。というわけで調整する1
NetAdaptって何
チャンネル数を細かく調整していくための方法。これも別の論文で提案されたもの。
1. 現在の設定を変更して、いくつかの「提案」をつくる。これらは、現在のモデルより$\delta$以上レイテンシが減っているようにすること。
* 例えば、$\delta = 0.01\left|L\right|$とすれば、0.999倍以下になるようにできる。
* レイテンシをいちいち測定するのは大変だが、設定によってほぼ確定するので設定ごとのルックアップテーブルを事前に作っておけば速い
 2. 設定の変更に応じてL2ノルムの小さなフィルタを消す。
3. $T$ステップfine tuneして大体の性能を推定する。
4. 最も性能の高い「提案」が生き残る。
これを、ほしいレイテンシが得られるまで繰り返す。
この論文における変更点としては、
2. 設定の変更に応じてL2ノルムの小さなフィルタを消す。
3. $T$ステップfine tuneして大体の性能を推定する。
4. 最も性能の高い「提案」が生き残る。
これを、ほしいレイテンシが得られるまで繰り返す。
この論文における変更点としては、
* 性能の高い提案ではなく、性能・レイテンシの減少比$\frac{\mathrm{\Delta Acc}}{\left|\mathrm{\Delta Latency}\right|}$の高い提案が生き残る。
* 以下の設定を追加
* expansion layerのサイズを減らす
* ボトルネック層のボトルネックサイズを一括で調整
* こうしないとresidual connectionがうまくいかなくなるので
効率的なネットワークデザイン
最初の方の層と、最終層が計算量的に重いことがわかったので、改善する。
復習
- 1x1 convの計算量は入力$C$チャンネル、出力$C'$チャンネルのとき$HWCC'$
- 3x3 depthwise convの計算量は$9HWC$(入力と出力は同じ$C$チャンネル)
最終層
 これに則ってそれぞれのconvのMulAdd計算量を出すと、
これに則ってそれぞれのconvのMulAdd計算量を出すと、 - $7^2 \times 160 \times 960 \approx 7\mathrm{M}$
- $9 \times 7^2 \times 960 \approx 0.42\mathrm{M}$
- $7^2 \times 960 \times 320 \approx 15\mathrm{M}$←こいつと
- $7^2 \times 320 \times 1280 \approx 20\mathrm{M}$←こいつがやばい
- $1^2 \times 1280 \times 1000 \approx 1.3\mathrm{M}$
チャンネル数を最後に広げるのは、豊富な特徴量のために不可欠だが、計算が重いのでどうにかしたい。
こんなに計算量が重い理由の一つは、1x1 convを7x7の解像度でやっているせいで計算量が約50倍になってしまっているためだろう。
これを解決するため、最後の層をaverage poolingのあとに移す。これで機能を保ったまま解像度が1x1に下がる。 また、この手法をとったのなら、計算量を減らすために一つ前に入れられていたボトルネックも不要だ。これでさらに計算量を減らすことができ、最終的に下図のようになる。 実際、計算量は
実際、計算量は - $7^2 \times 160 \times 960 \approx 7\mathrm{M}$
- $1^2 \times 960 \times 1280 \approx 1.2\mathrm{M}$
- $1^2 \times 1280 \times 1000 \approx 1.3\mathrm{M}$
になっており、合計計算量は$43.72 \mathrm{M} \rightarrow 9.5 \mathrm{M}$、約$30\mathrm{M}$の減少。これは7msに相当し、全実行時間の11%にもなる。
この変更による精度の減少はほぼない。最初の層
現行のモデルは、3x3コンボリューションフィルタ32個を使うことが多い。だが、これらはお互いの鏡像であることがおおい。 そこで、フィルタを減らす代わりに非線形関数を変えてムダを減らした
最終的に他の非線形関数と同じような性能を出したhard swishを使うことにした。
ReLUやswishで32フィルタを使ったときと同等の性能をh-swish&16フィルタで達成。$10\mathrm{M}$=1.2msの削減に成功した非線形関数
既存研究でswishという非線形関数をReLUの代わりに使うことが提案されている。 $$ \mathrm{swish}\ x=x \cdot \sigma (x) $$ だがsigmoidは重いのでどうにかしたい。というわけでhard swishという関数を使うことにする $$ \text{h-swish}\ \left[ x \right] = x \frac{\mathrm{ReLU6} (x+3)}{6} $$ ただし、$\mathrm{ReLU6}(x) = \min (\mathrm{ReLU}(x), 6)$ これは、計算が軽いだけでなく、量子化されているときにsigmoidの近似により発生するかもしれない誤差が小さくなること、
また実際には $$ \text{h-swish}(x) = \begin{cases} 0\ &(x<0)\\\ x(x+3)/6\ &(0<x<3)\\\ x &(3<x) \end{cases} $$ のように最適化でき、関数呼び出しは行われないので、メモリアクセスを減らしてレイテンシを劇的に下げることができる。嬉しい。
ちなみにこれはすでにTFLiteに実装されており、デフォルトで使えるそう。 しかし、h-swishは小さいとはいえやはり速度に影響を及ぼす。できるだけReLUも使いたい
しかし、h-swishは小さいとはいえやはり速度に影響を及ぼす。できるだけReLUも使いたい
ここで、深い層のほうが活性化関数の使われる回数(=コスト)は一般に少ないことを利用する - 深くなると解像度が半分になり、したがって使われる回数は1/4だが、チャンネル数はそんなに増えないので
実際、今回は最初の層と後半の層のみにh-swishが使われている。詳しくは以下の表を見よ。



効率的なセグメンテーションモジュール
セグメンテーションの手法の一つDeepLabでは、下の図2
 のように、複数のdilated convを並列的に行って情報を集約するという方法が取られていた。これで、様々なスケールの特徴量を同時に計算できる。
のように、複数のdilated convを並列的に行って情報を集約するという方法が取られていた。これで、様々なスケールの特徴量を同時に計算できる。
具体的には以下のようなモデルとなる。 しかし、計算が死ぬほど重い割にそんなに性能に効果がないことが指摘され、average poolingだけでいいじゃんとなった。
しかし、計算が死ぬほど重い割にそんなに性能に効果がないことが指摘され、average poolingだけでいいじゃんとなった。

- 3行目と5行目。ASPPにより計算量が倍以上になっているのに性能は0.4%弱しか上がってない。
これにより提案された3のがReduced-ASPP、略してR-ASPP。atrous convを並列的に行う代わりに1x1 convとGAPだけですませるというもの。
本論文では、それを更に改良したLite R-ASPP、略してLR-ASPPを提案する。
名前つけるの好きだな……
- Squeeze-and-Excitationをまねて、GAPっぽい仕組みを使う
- 広い範囲のpoolingを大きいstrideで行って、情報を集約しつつ計算量を節約
- このあとこれに対して1x1 convを行わなければいけないので
- それをスケールとして使う
- 広い範囲のpoolingを大きいstrideで行って、情報を集約しつつ計算量を節約
- 最後に解像度の高い層の結果と足し合わせる
結果
Classification Task



- 解像度を下げると良い結果が出るが、セグメンテーションや物体検出など、高い解像度を要求するタスクには使えないので注意
Ablation Study

- @16とはつまり全てh-swishという意味。当然計算量は少し多くなる……が性能は高めになる


Detection
 $\dagger$の改良は、性能を変えないままレイテンシを15%下げている。ImagenetとCOCOには異なる形状の特徴量抽出器を使ったほうがいいのかもしれない。
$\dagger$の改良は、性能を変えないままレイテンシを15%下げている。ImagenetとCOCOには異なる形状の特徴量抽出器を使ったほうがいいのかもしれない。 - Imagenetは1000クラスあるが、COCOは90クラスしかないので、必要とされるチャンネルの豊富さが違うためと考えられる
Semantic Segmentation

- 物体検出のときと同じように、最後のブロックのチャネル数を2で割ってもあまり性能は変わらず、速度を大きく向上させられる(1行目vs2行目、5行目vs6行目。以下、「行目」を略す)
- 今回のタスクであるCityscapesは19クラスしかなく、やはりムダがあるのだろう
- LR-ASPPはR-ASPPと比べ性能がよく速度もわずかに速い (2vs3, 6vs7)
- Segmentation Headのフィルタ数を256→128に減らすと、性能が少し落ちるが速度が上がる(3vs4 7vs8)
- 同じ設定なら、V3はV2と同じような性能でわずかに速い(1〜4vs5〜8)
- V3-Small(11)はV2 0.5(9)と同程度の性能だがより速い
- V3-Small(11)はV2 0.35(10)と同程度の速度だがかなり性能がいい

- atrous convを使えばもちろん勝てる、使わなくてもやや性能が悪いがそれでも勝ってる、計算量的にも圧勝 写真は、特に明記したものを除いて、リンクされている論文の中のいずれかのスクリーンショットです。
OpenPoseで実装されているHand推定の論文「Hand Keypoint Detection in Single Images using Multiview Bootstrapping」を読みました
CTOの幅野です。
OpenPoseのHand Keypoint検出モデルの論文を読みましたの解説していきます。
概要
RGB画像から手の部位を検出するモデルの学習方法を提案。
Pose推定などで利用されているConvolution Pose Machinesを手の部位検出に応用することを考える。
Depthを利用した検出方法と同等の精度を達成した。
Convolutional Pose Machine(CPM)
Convolutionで構成される、RGB画像からPoseの各部位のヒートマップを出力するネットワーク
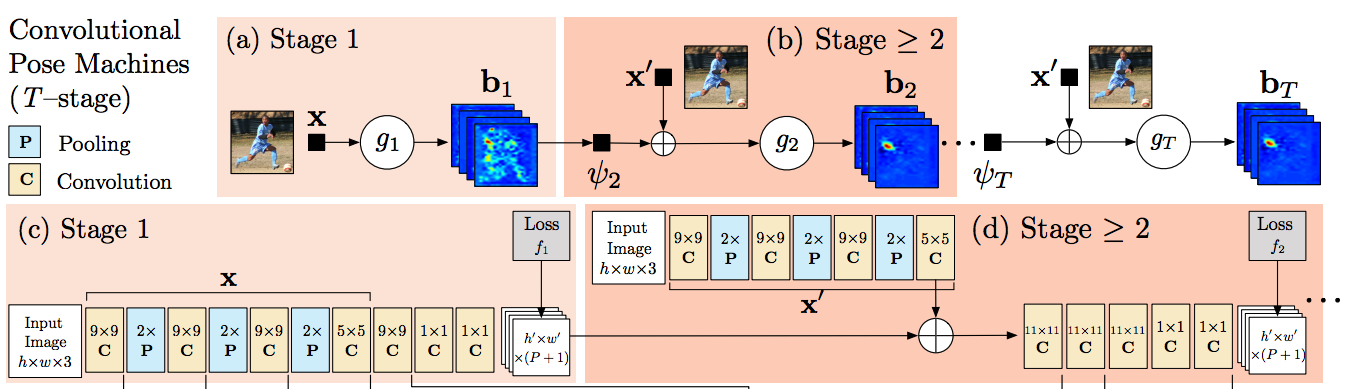
Stageごとにヒートマップが出力され、それぞれに対してヒートマップの損失関数を計算し学習を行う。 多段にするは他の部位ヒートマップ情報を利用すること。 本論文では手の検出にこのモデルを応用する。
手の部位検出までの流れ
RGB画像から手の部位を検出するまでに2段階の工程を利用している。
- 手のBounding Boxの検出、Crop
- Cropした画像を元に手の部位を検出
2はCPMを利用して部位を検出するが、そのために手の部分を1で抽出している。 手の部分を抽出するためにOpenPoseによって推定した手首と肘を利用する。 手の中心座標は肘から手首への延長線上にあると仮定する。 具体的な計算方法は肘から手首の長さの0.15倍を延長した点を手の中心座標としている。 Bounding Boxの大きさは学習時には全ての手の部位が包含できる最大サイズ$B$を2.2倍したものとし、 テストの推論時には$B$をOpenPoseで推定したHeadからBottomまでの長さの0.7倍として計算する。
Cropした画像は以下のようになる。

学習の問題点
手の部位を検出する際に出てくる問題は教師をつけることが難しいという点である。 その理由は以下の画像のようにオクルージョンが発生するためである。
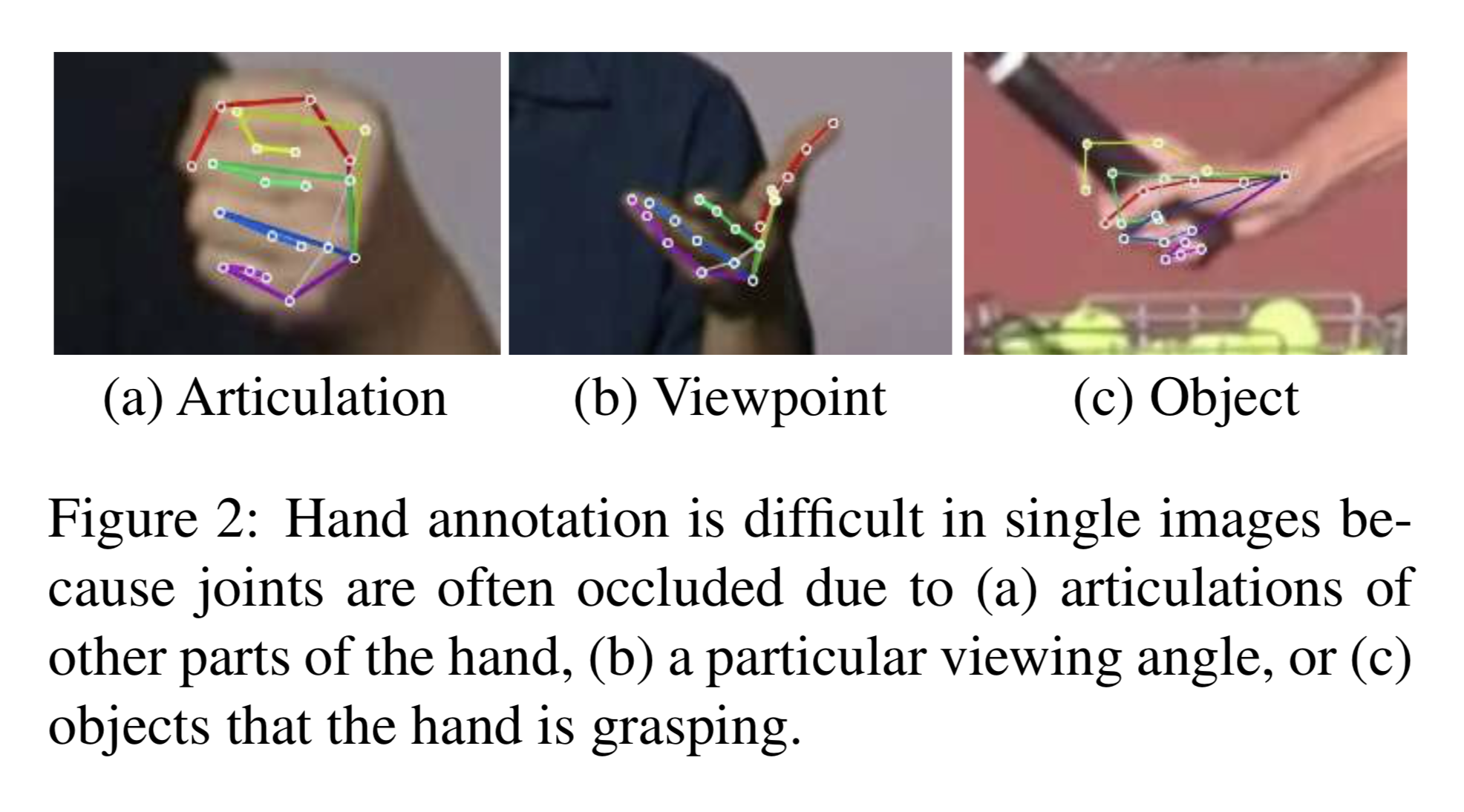
手の部位はPoseと比較すると「握る」などの動作があるためオクルージョンを起こす確率が高い。 そしてこのオクルージョンしている画像に対してほぼ確実に教師をつけることは困難である。
BootStrappingを利用した学習
本論文では上の問題に対してMulti Cameraの情報を利用することで教師のない画像に教師をつけて再学習するBootStrapping手法を提案している。
なお、この手法を利用するための前提として教師がつけられていない画像には以下の条件が設定されている。
- キャリブレーションされた複数カメラによって同フレームで撮影された画像が用意されていること
大まかな手順は以下の通りである。
- 教師のついている画像を利用してCPMのモデル$d_0$を学習
- $d_0$を使って教師のついてない画像を推論, 3次元情報の抽出
- Confidense Scoreの高い順に画像をソートし、上位N個を学習データに加えて再学習

3次元情報の再構成を利用して教師を作成
この手法は同じフレームで撮影された複数画像を元に3次元の部位座標を再構成することで、教師を新たに付与している。
学習した$d_0$を利用して教師のついていない画像$I_vf$に対して部位の検出を行う。
$$
\mathcal{D} \leftarrow\left\{d_{i}\left(\mathbf{I}_{v}^{f}\right) \text { for } v \in[1 \ldots V]\right\} (5)
$$
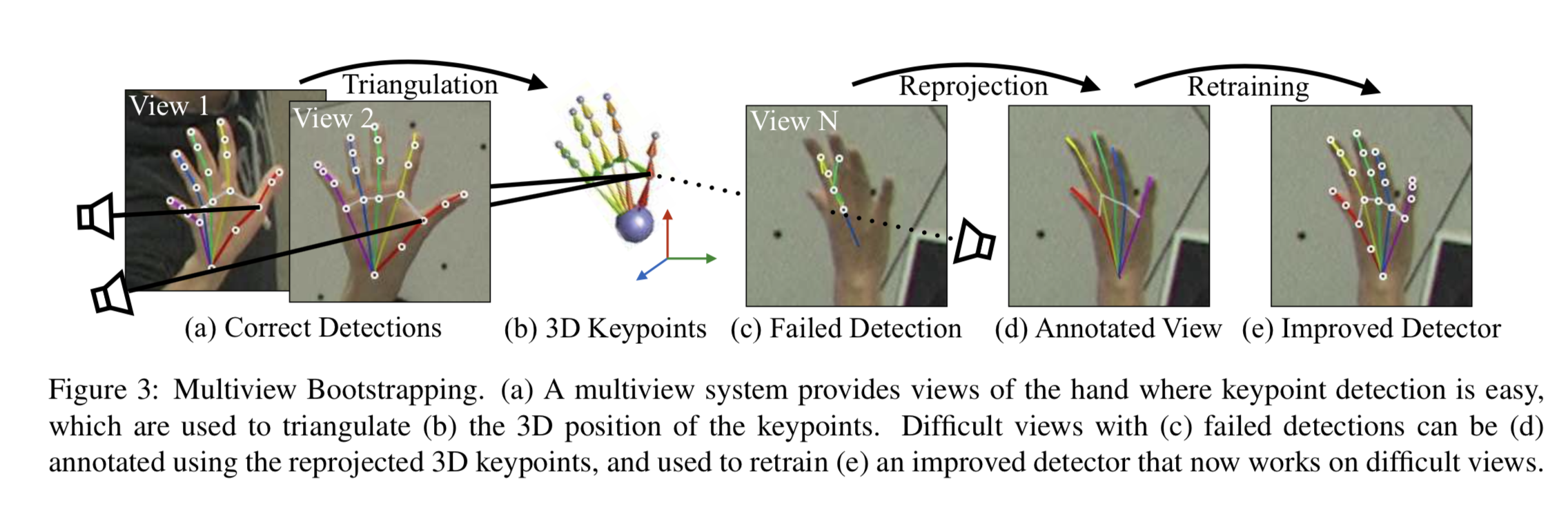
これらを元に3次元情報を構築するのだが、外れ値をなるべく減らすようにConfidence Scoreが$\lambda$以下の関節点は除去する。 検証時は$\lambda=0.2$としている。
上図のように2つの2次元情報$\mathbf{x}_{p}$とカメラのキャリブレーションを元に3次元情報$\mathbf{X}_{p}^{f}$を構成することができる。
同フレームに$V$個の画像があった場合、${}_V C_2$個の3次元情報の候補が作成できる。
この中から以下の式が最小になる3次元情報を採用する。 $$ \mathbf{X}_{p}^{f}=\arg \min_{\mathbf{X}} \sum_{v \in \mathcal{I}_{p}^{f}}\left|\mathcal{P}_{v}(\mathbf{X})-\mathbf{x}_{p}^{v}\right|_{2}^{2} (6) $$
追加する学習データの選択
本手法では新たに教師を付けたデータを学習データとして追加するときにランダムに追加するのではなく$d_0$で推定されたConfidence Scoreの高いフレームを追加する。 スコアリングの計算は以下の通りで各フレームごとに計算する。
$$ \operatorname{score}\left( \left\{ \mathbf{X}_{p}^{f} \right\} \right)=\sum_{p \in[1 \ldots P]} \sum_{v \in \mathcal{I}_{p}^{f}} c_{p}^{v} (7) $$
$score$を利用して上位$N$個を学習データとして追加したものを$\mathcal{T}_{i+1}$とし、再学習を行う。

結果
本手法の検証を行うためにMPII、NZSLという手が写っているデータセットに教師をつけた。 MPIIは1300、NZSLは1500の手の学習データを作成し、2000枚を学習用、800枚をテスト用に利用した。
学習は"Render", "Manual", "Mix"という3種類の方法を利用して検証を行っている。
- Render: UnrealEngineを利用して11000枚の合成画像を元に学習
- Manual: MPII, NZSLの学習データを利用して学習
- Mix: RenderとManualを組み合わせて学習
なお、これらの学習データに加えて、教師のないPanoptic Studio DatasetでMultiview Bootstrappingを行っている。
Panoptic Studio Datasetは31個のHDカメラで撮影されたデータセットである。
一つの指標として$PCK$という手法を利用して検証を行っている。

PCKによる検証
MPI, NZSLのテストデータに対してのPCKの評価が以下の図である。
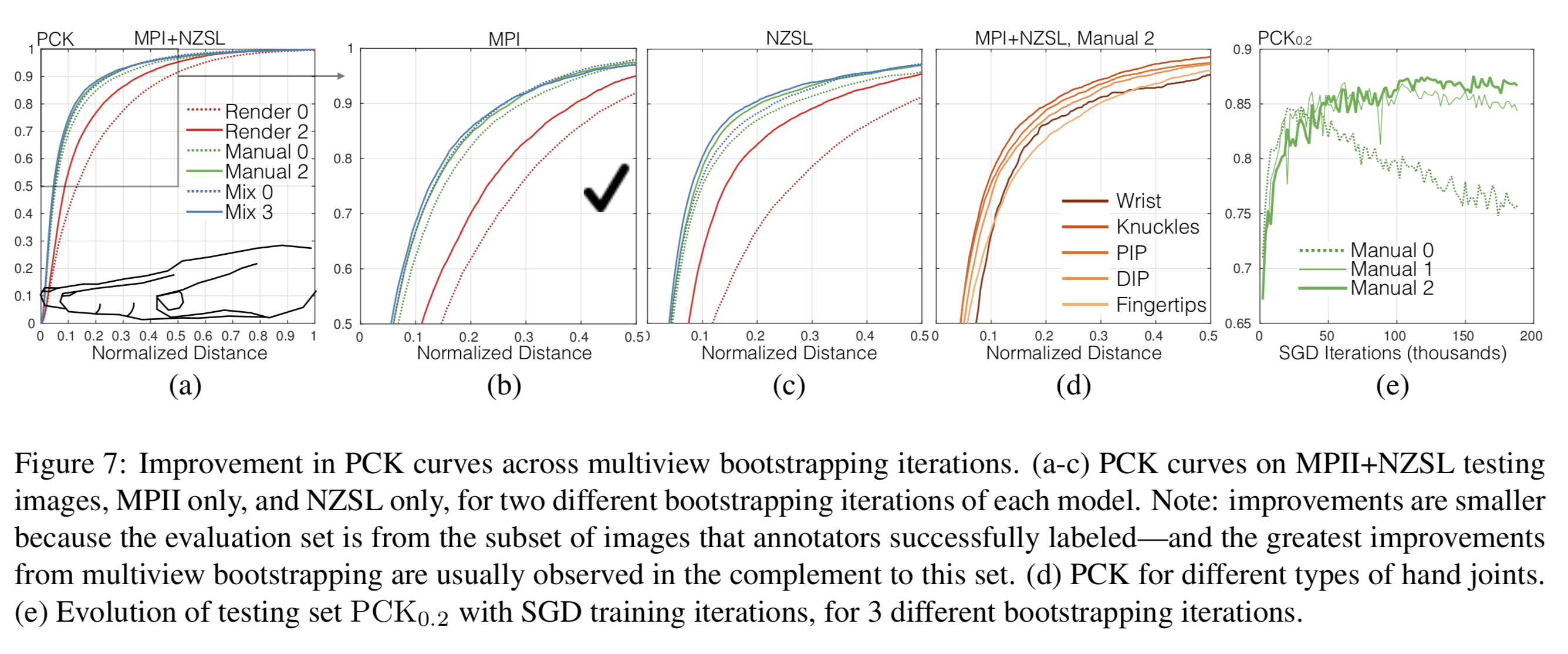
縦軸がPCK, 横軸が[0, 1]で正規化された距離の閾値である。
の値が低いときにPCKが高いほど精度が良い。
(a)のモデルで記載されてある番号("Render 0")などはMultiview Bootstrappingによって再学習した回数である。
(a)を見ると、Bootstrappingをすることによって精度が向上しており、Mixが一番高い性能を出している。
(e)は縦軸がのときのPCK、横軸がSGDのiterationを表している。
これを見ると再学習を加えることによって、iterationを増やしても過学習がおきにくいロバストなモデルを構築できていることがわかる。
各モーションに対する2次元のピクセル誤差の検証
モーションに対しての手の部位のピクセル誤差を検証している。 また、この検証ではDepthを元に手の部位を検出する手法と精度を比較している。

既存手法と比較して精度が高いとは言えないが、RGB画像の手法として同等の精度を出せている。
3DPose推定モデル「RepNet」を読んでみました
CTOの幅野です。
CVPR2019で発表された3DPose推定の論文RepNetを解説します。
概要
2DPoseから3DPoseを推定するモデルを提案した論文です。
本論文では既存モデルは学習データに類似したシーンは3DPoseをうまく推定できるものの、カメラの位置やPoseが学習データと異なるものに対する3DPose推定がうまくいっていない問題をあげております。
この過学習問題への解決方法として著者らは2つの方法を考案しています。
一つは2DPoseの分布から3DPoseの分布への写像をAdversarial Lossを利用して学習する方法で、もう一つは推定した3DPoseが元の2DPoseへ再構成の誤差を付与して学習する方法です。
この2つの方法を元にRepNetというモデルを提案し、弱教師あり学習において高い精度を出しています。
モデルアーキテクチャ
以下の図がRepNetのアーキテクチャ図です。

RepNetは4つのネットワークで構成されています。
- Pose Generator Network
- Camera Network
- Critic Network
- Reprojection Network
それぞれのモデルについて説明していきます。
Pose Generator Network
Pose Generator Networkは2DPose座標を入力し、3DPose座標を出力するネットワークです。このネットワークを学習するためにその他のネットワークを付与しています。
ネットワーク自体はFull Connected Layerで構成されたネットワークで活性化関数はleaky ReLUを利用しています。
Camera Network
2DPose座標を入力し、2×3の行列であるカメラパラメータKを出力するネットワークです。
このカメラパラメータと推定した3DPoseを利用して元の2DPoseを再構成するために利用します。
Critic Network
Pose Generator Networkで生成された3DPoseが3DPoseの分布に従っているかどうかを判定するDiscriminator Networkです。Wasserstein Lossを利用して学習します。
Reprojection Network
Pose Generator Networkで生成された3DPoseとCamera Networkで出力されてカメラパラメータを利用して元の2DPoseを再構成するネットワークです。
モデルの学習方法
次にそれぞれのネットワークの詳細な内容と学習方法について説明していきます。
2DPoseの再構成によるReprojection Loss
既存の3DPose推定モデルが過学習している一つの要因として、著者らは推定した3DPoseが元の2DPoseへ再構成できるという制約を無視していると主張しています。
RepNetは3DPoseとその3DPoseをどの位置から投影したかを表すカメラパラメータがあれば2DPoseを再構成できるという仮説のもと構成されています。
この再構成の学習方法について説明します。
まずPose Generator Networkで生成した3DPoseを$\boldsymbol{X} \in \mathbb{R}^{3 \times n}$とし、Camera Networkで出力されたカメラパラメータを$\boldsymbol{K} \in \mathbb{R}^{2 \times 3}$)とします。
この2つの行列の積を推定した2DPoseとします。
$$ \boldsymbol{W}^{\prime}=\boldsymbol{K} \boldsymbol{X} $$
この推定した2DPoseと入力した2DPoseの再構成誤差を以下のように定義します。
$$ \mathcal{L}_{r e p}(\boldsymbol{X}, \boldsymbol{K})=|\boldsymbol{W}-\boldsymbol{K} \boldsymbol{X}|_{F} $$
Fはフロベニウスノルムを表しています。
KCS Layerを導入したWasserstein Loss
Pose Generator Networkの学習はReprojection Layerに加えて、Critic Networkを利用してAdversarial Lossで学習を行います。
Adversarial LossはWGANで利用されているWasserstein Lossを利用します。
Critic Networkの図を以下で示します。

そして、このCritic NetworkにはKCS Layerという層を利用しています。
このKCS LayerはHuman Poseの性質を考慮した情報を抽出する層です。
具体的には人間の関節点の角度や長さなどを抽出します。
そしてその抽出を2つの行列のみを利用して計算をすることができます。
$$ B=X C $$
$$ \boldsymbol{B}=\left(\boldsymbol{b}_{1}, \boldsymbol{b}_{2}, \ldots, \boldsymbol{b}_{b}\right) $$
この計算について詳細に説明します。
$$
\begin{array}{l}{\qquad b_{k}=p_{r}-p_{t}=X c} \ {\text { where }} \ {\qquad c=(0, \ldots, 0,1,0, \ldots, 0,-1,0, \ldots, 0)^{T}}\end{array}
$$
pは各関節のPoseの座標を表しており、PrとPtは結合している関節点同士です。
この2つの座標の差分を計算したいのですが、直接計算をするのではなく、cというベクトルを利用してbを計算します。
このcをすべてのBoneに対して用意することでC行列を作成することができ、上記の計算を行列積として計算できます。
これにより計算されたBを追加してWasserstein Lossで学習を行います。
Camera Networkの制約を考慮したCamera Loss
Camera Networkで出力されるカメラパラメータKはコンピュータグラフィックスの透視投影変換という手法で利用される透視投影行列とみなしています。
そして透視投影行列は以下の性質を持っています。
$$
\boldsymbol{K} \boldsymbol{K}^{T}=s^{2} \boldsymbol{I}_{2}
$$
sは投影するPoseのスケールを表しており、この式の制約に従うようにCamera Networkを学習する必要があります。
しかしこのsは学習時には未知な値なのでsを損失関数に入れないように変形をおこないます。
sについて式に変換したものが以下となります。
$$
s=\sqrt{\operatorname{trace}\left(\boldsymbol{K} \boldsymbol{K}^{T}\right) / 2}
$$
この式を元の式に代入して、定義した損失関数が以下になります。
$$
\mathcal{L}_{c a m}=\left|\frac{2}{\operatorname{trace}\left(\boldsymbol{K} \boldsymbol{K}^{T}\right)} \boldsymbol{K} \boldsymbol{K}^{T}-\boldsymbol{I}_{2}\right|_{F}
$$
まとめるとRepNet以下の3つの損失関数を元に学習を行います。
- Wasserstein Loss
- Reprojection Loss
- Camera Loss
検証
3DPoseデータセットであるHuman3.6とMPI-INF-3DHPを利用して検証を行っています。
評価方法はMean Per Joint Positioning Error(MPJPE)を利用して行動ごとに算出しています。
Protocol1
Protocol1はPose Generator Networkで出力された3DPoseをそのままMPJPEで評価したものです。
比較しているモデルは教師ありのタスクで学習してモデルでそれらと比較すると高い精度を出せているとは言えません。
しかし、Ground Truthな2DPoseを利用すれば同等の精度を出せるモデルであることを示しています。

Protocol2
Protocol2は推定した3DPoseに対してrigid alignmentという手法を利用して3Dから2Dに戻したものをMPJPEで評価をしています。
[44], [35]は弱教師あり学習のタスクで提案されたモデルでそれよりも高い精度を出しています。
また、KCS Layerをいれることによって精度が向上しています。

Boneの長さの検証
KCS Layerを導入することによってHuman Poseの左、右のBoneの長さの誤差が低くなっているかどうかを検証しています。
本論文ではSymmetry Errorとして左、右のBoneの長さの差分を計算しています。
 結果をみるとKCS LayerをいれることでBoneのSymmetry Errorが下がっていることがわかります。
結果をみるとKCS LayerをいれることでBoneのSymmetry Errorが下がっていることがわかります。
3DPCK, AUCの検証
MPJPEに加えて3DPCKとAUCの評価を加えて行っています。
3DPCKは関節点が正しい位置を推定している比率を計算するための手法で、関節点が一定の値(引用している論文では150mmとしています)をthresholdとして正しい位置にあるかどうかをずれを利用して判定します。
AUCは3DPCKのaccuracy計算をAUCに置き換えたものです。
MPI-INF-3DHPのテストデータセットに対して、3DHPもしくはHuman3.6Mで学習したモデルを利用して評価しています。

Grouped Convolutionのハイパーパラメータを最適化する「clcNet」を読んでみました
インターンの林です。
社内勉強会でclcNetについて発表しました。
概要
- clcNet提案
- CDG(Channel Dependency Graph)とCRF(Channel Receptive Field)を新たな分析のツールとして使用
- グループ化畳み込みに変わり、新たな畳み込みのIGC(Interlaced Grouped Convolution)を使用
- ImageNet-1Kデータセットにおいて、既存のモデルより高い計算効率とパラメーター数減少を達成
背景
- 現在では計算効率の良い畳み込みの手法として、dw 畳み込みやグループ化などが使われている
- モバイルデバイスに使えるようなCNNは計算効率とメモリ効率のが重要である
- 上記の畳み込み手法に少し変更を加え、計算効率を向上させたのがclcNet
CLC (Channel Local Convolution)
- 出力チャネルの計算が一部の入力チャネルのみに依存している畳み込み
- dw 畳み込み, グループ化畳み込み
- CLCの受容野は空間次元とチャネル次元の両方に沿って局所的
- 受容野: ある特徴マップの一画素が集約してる前の層の空間の広がり
- Figure 1で概念的に示している

CDG (Channel Dependency Graph)
- チャネルの計算依存性を示す2部グラフ
- Node: チャネル
- Edge: 依存性
- 上のNodeが入力
- 下のNodeが出力を表す
- 出力->入力というように表現される
- CDGを使うことで、モデル設計のためのチャネル依存の分析が簡単になる
- 積み重ねたCLCカーネルを、通常畳み込みに近似させるための分析に使う

- 積み重ねたCLCカーネルを、通常畳み込みに近似させるための分析に使う
チャネル受容野 CRF (Channel Receptive Field)
- 出力チャネルが依存する入力チャネルのサブセット
- FCRF (Full Channel Receptive Field)
- 出力チャネルが入力チャネルのすべてに依存している状態
- CRFサイズ
- 依存している入力チャネルの数
仮説:
- FCRFを達成することは、CLCが通常Convolutionの正確な近似する上で必要である
CGDを使って他のモデルを分析してみる
- FCRFが達成されているモデルに使われている畳み込み
- ResNetのbottlenetck structure
- ResNeXt block
- Depthwise Convolution for MobileNet and Xception

- FCRFが達成されていないモデルの畳み込み
- dw畳み込み & 1x1畳み込みをグループ化畳み込みに

- FCRFが達成されていない
- 結果、クラス分類において従来よりも低い精度になった
- ShuffleNetの論文でも、Shuffleなしのdw & 1x1畳み込みが試され、Shuffleありと比べて精度が下がったと言われていた
IGC (Interlaced Grouped Convolution)
- MobileNetやXceptionでdw畳み込みや1x1畳み込みが効果的であると証明された
- だが1x1畳み込みの占める計算量は多い
- さらなるコスト効率化のために、1x1畳み込みを変更したい
- 1x1畳み込みをグループ化畳み込みにする
- Figure 4で示した通り、FCRFもなくなり、精度も下がる
- IGC:
- グループ化畳み込みのチャネル依存パターンを変えることでFCRFを実現

CLC Block

FCRFのルールとコスト最小化
- M : input channels
- N : output channels
- L : intermediate channels
- g1: IGC カーネルのgroup parameter
- g2: GC カーネルのgroup parameter
CRF(Channel Receptive Field): 出力チャネルが依存する入力チャネルのサブセット CRF size: 依存している入力チャネルの数
- IGC カーネルのCRFサイズ : M/g1
このCLC BlockがFCRFを達成するためには、GCのCRF size(L/g2)がIGCカーネルのgroup parameter(g1)より大きくなる必要がある
- $ L/g{2} \geq g{1} $ すなわち $ g{1}g{2} \leq L$
コスト (Computational cost)最適化の式

A=9とき最小化されたパラメーター

- A: spatial area of the convolutional kernel
- A = 9 for 3x3 kernel
- A: spatial area of the convolutional kernel
モデル

検証
5.1 Classification Accuracy of clcNet
- state-of-the-art modelであるMobileNetと比較
- a, b, c, d (layer configurations)
- 精度が良かった2つをclcNet-A, clcNet-B

- 後ろのlayer(c or d)を増やすことが、前のlayer(a or b)を増やすことよりも、精度が上がることが分かる
5.2 The importance of FCRF(Full Channel Receptive Field)

5.3 Comparision with Previous Models

