Deep Learning推論用デバイスその2 NVIDIA Jetson Nano
はじめに
この記事はDeepLearning推論用デバイスまとめ記事の第二弾です。第二弾ではNVIDIAが提供しているJetson Nanoについて紹介します。他のデバイスに関しては下記にまとめられています。
NVIDIA Jetson Nano

(引用:https://developer.nvidia.com/sites/default/files/akamai/embedded/images/jetsonNano/Jetson-Nano_3QTR-Front_Left_trimmed.jpg)
JetsonシリーズはNVIDIAが提供しているGPUデバイスの一つで、DeepLearningモデルの学習ではなく推論に特化したハードウェアです。Jetsonは以前紹介したIntel Nural Compute Stick2とは異なり推論プロセッサのみをUSBで接続するのではなく、開発ボード全体をデバイスとして提供しています。以下がスペック表です。
| 要素 | Spec |
|---|---|
| GPU | 128-core Maxwell |
| CPU | Quad-core ARM A57 @ 1.43 GHz |
| Memory | 4 GB 64-bit LPDDR4 25.6 GB/s |
| Storage | microSD (not included) |
| Video Encode | 4K @ 30 | 4x 1080p @ 30 | 9x 720p @ 30 (H.264/H.265) |
| Video Decode | 4K @ 60 | 2x 4K @ 30 | 8x 1080p @ 30 | 18x 720p @ 30 (H.264/H.265) |
| Camera | 1x MIPI CSI-2 DPHY lanes |
| Connectivity | Gigabit Ethernet, M.2 Key E |
| Display | HDMI 2.0 and eDP 1.4 |
| USB | 4x USB 3.0, USB 2.0 Micro-B |
| Others | GPIO, I2C, I2S, SPI, UART |
| Mechanical | 100 mm x 80 mm x 29 mm |
(引用:https://developer.nvidia.com/embedded/jetson-nano-developer-kit)
気になる点について紹介していきます。
128-core Maxwell
MaxwellとはNVIDIA GPUのマイクロアーキテクチャのコードネームです。Tesla, Fermi, Kepler, Maxwell, Pascal, Voltaと世代ごとに名付けられていて、Jetson NanoではMaxwellマイクロアーキテクチャ仕様のCUDAコアが128個搭載されています。同じJetsonシリーズで以前から発売されているJetson TX系統は256-core Pascalが搭載されているのでその部分で見ると、Jetson Nanoは性能を落としています。価格と必要なスペックによってTXとNanoを選択する形になります。
Memory
Jetson NanoにはGPUだけでなく、CPUも搭載されております。また、Memoryに関しては4GB積まれておりこのRAMをCPU・GPUともに共有して利用します。
その他周辺環境について紹介していきます。
NVIDIA Jetpack
JetpackとはJetsonシリーズのデバイス向けのSDKです。NVIDIA製のGPUをDeepLearningの学習などで利用するためにはCUDAやCUDNNなどといったライブラリが必要でした。それらのライブラリをJetsonシリーズ向けにまとめられているのがJetpackです。なおJetpackの中に推論をNVIDIA GPUに最適化するためのライブラリであるTensorRTが入っています
推論速度
JetsonNanoの推論速度の評価に関してはNVIDIA社の技術ブログで紹介されています。
こちらがJetsonNano上でTensorRTを利用したモデルに対してのFPSを計測したヒストグラムです。
 (引用:https://devblogs.nvidia.com/wp-content/uploads/2019/03/imageLikeEmbed-1024x510.png)
SSD-MobileNet-v2: 39FPS、Inception V4: 11FPS 達成しているそうです。また記事の後半にはGoogleが提供しているデバイスであるEdgeTPUとの性能評価が掲載されています。画像分類タスクにおけるMobile-Netv2や物体検出のSSD-Mobile-Netv2などを見るとEdgeTPUのほうがFPSが勝っています。ただ、多くのモデルについてはそもそもEdgeTPUで推論することができないものが多くDNR(did not run)と評価されています。この結果を見ると推論速度のみの観点ではEdgeTPUに載せられるモデルはEdgeTPU、載せられない場合はJetson Nanoという順番になりそうです。
(引用:https://devblogs.nvidia.com/wp-content/uploads/2019/03/imageLikeEmbed-1024x510.png)
SSD-MobileNet-v2: 39FPS、Inception V4: 11FPS 達成しているそうです。また記事の後半にはGoogleが提供しているデバイスであるEdgeTPUとの性能評価が掲載されています。画像分類タスクにおけるMobile-Netv2や物体検出のSSD-Mobile-Netv2などを見るとEdgeTPUのほうがFPSが勝っています。ただ、多くのモデルについてはそもそもEdgeTPUで推論することができないものが多くDNR(did not run)と評価されています。この結果を見ると推論速度のみの観点ではEdgeTPUに載せられるモデルはEdgeTPU、載せられない場合はJetson Nanoという順番になりそうです。
参考文献
Deep Learning推論用デバイスその1 Intel NCS2
はじめに
今回は深層学習用のエッジコンピューティングデバイスの市場調査を行ったので、まとめました。
調査したデバイス
調査したデバイスは以下の3つです。
デバイス間の比較をする前にまず、それぞれのデバイスの特徴などをまとめていこうと思います。 今回の記事ではIntel Neural Compute Stick2について紹介したいと思います。
Intel Neural Compute Stick2

Neural Compute Stick2(NCS2)はIntelが発売したDeepLearning推論用のUSB型外部演算装置です。既存のマシンに対してUSBからNCS2を接続することで、演算をさせることができます。NCS2は以前に発売した「Movidius Neural Compute Stick」の新型となります。公式サイトより、旧型と比べ8倍ほど推論時間が速くなっていると記述されています。
こちらがNCS2のスペック表です。
| 要素 | Spec |
|---|---|
| プロセッサ | The Intel Movidius Myriad X VPU |
| 開発環境 | The Intel Distribution of OpenVINO toolkit |
| 対応OS | Ubuntu 16.04.3 LTS (64 bit),Windows 10 (64 bit), or CentOS 7.4 (64 bit) |
| 対応フレームワーク | TensorFlow, Caffe, Apache MXNet, ONNX(PyTorch, PaddlePaddle) |
| 接続方法 | USB 3.0 Type-A |
| サイズ | 72.5mm X 27mm X 14mm |
| 運用温度 | 0° - 40° C |
Myriad X VPU
Intel NCS2にはMyriad X Vision Processing Unit(VPU)というプロセッサが搭載されています。VPUは内部にはSHAVE processorと呼ばれるVLIWベクトルプロセッサがあり、旧世代のNCSにさらに4個追加した計16個のSHAVE processorが搭載されています。このSHAVEプロセッサによってニューラネットワークの推論計算を一部分並列化することができます。
Open VINO
IntelはNCSと同時にDeepLearning用のSDKであるOpenVINOを発表し、NCS2にも対応させています。 OpenVINOはIntelが提供しているハードウェアに対して最適化されたC++の推論APIです。 OpenVINOのドキュメント また、IntelからONNX RuntimeのプロバイダとしてOpenVINOをサポートするようなコードがforkされて実装されています。 https://github.com/intel/onnxruntime/tree/master/onnxruntime/core/providers/openvino 今後、正式にサポートされることになれば、対応しているFramework(Tensorflow・Caffe)のみならず、様々なFrameworkからOpenVINO経由で推論できることになりそうです。
対応OS
旧世代ではUbuntuのみの対応でしたが、Windows・CentoOSなど対応OSが増えました。 他にもRaspbianなども対応されており、OpenVINOのツールキットをインストールできる環境であればそのOSが載っているマシンにNCS2を接続させることで推論させることができます。
対応フレームワーク
旧世代のNCSではCaffe, Tensorflowのみ対応ということですが、NCS2ではそれに加えMXNetやONNXなどに対応しています。特にONNXに対応したことによってPyTorchなどで実装されたモデルをONNXに変換してNCS2で推論するなどといったことが可能になっております。
運用温度
運用温度は0度〜40度と公式では記述されていますが、フォーラムなどを見ると推論時の温度が高くなってしまう問題が一つのトピックになっています。
今後について
ONNX対応による様々なフレームワークへの対応環境、OpenVINOによる推論最適化などがNCS2を通してやられています。またIntelは2019年の4月にVNNI命令セットを発表しており、CascadeLakeというCPUには畳み込み層の計算を高速化するような命令セットが用意されています。このあたりの命令セットもVPUなどに搭載されるとより高速な処理が可能になるのではと予想されます。また、熱問題に関してはフォーラムで議論されていますが、NCS2をプロダクトとして利用する場合には重要な要素となるので、一番最初にUSBスティック型推論デバイスを出したIntelが今後どのように対応していくかは注目です。
参考文献
Xception仮説によりConvolution層を軽量化「Xception : Deep Learning with Depthwise Separable Convolutions」を読んでみました
インターンの中村です。
今回はXceptionの論文を読みました。
Oct 2016, by Francois Chollet (Kerasの作者)
arxiv: https://arxiv.org/abs/1610.02357
何がすごい?
Inception概説
Inceptionをつかったモデルの一つであるGoogLeNetはInception Moduleを積み重ねてできている。

- GoogLeNet(とそれに使われたInception Module)は、モデルアーキテクチャを手動で探索せずとも、いろんな深さの層を並列に組んでやって学習すれば自動で探索してくれるのでは?というアイデアに基づいている。
- しかし、これをチャンネル同士の関係性 (channel correlation) の分離という別の視点から考察することにより、Xceptionモデルが生まれた。以下に詳説する:
Inception Moduleでは先に1x1 convでチャンネル数を減らし、その後で3x3 convなどをする(図1)。

シンプルにしたのが図2。
これは、1x1 convの出力チャンネルが3倍あって、それを3x3 convが分担して受け取っているとも考えられる。
すなわち
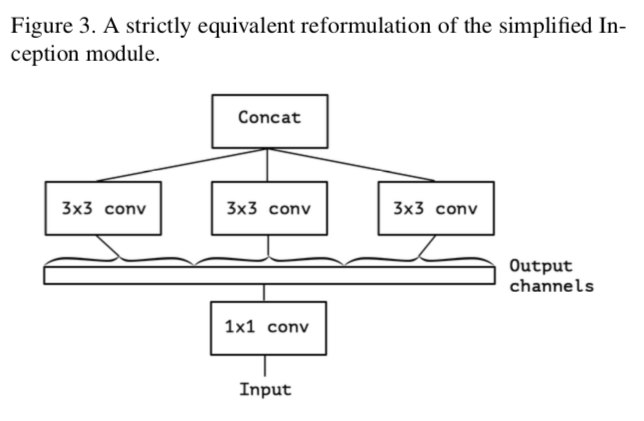
更に、これを極端(eXtreme)にするならば

こうなる。
3x3 convの数自体は増えるが、それぞれのconvに対するinput channelを少なくしている(というか1)ので計算量が激減する。
この時、もはや3x3 convは1チャンネルしか入力されていないので、チャンネル同士の関係性を見ることはない。
これをXception Moduleと呼ぶ。
Inception仮説, Xception仮説
Inception Moduleが正しく動くには、channel correlationと空間同士の関係性 (spatial correlation) の計算が(ある程度)分離可能という仮説が必要。 Xception Moduleが正しく動くには、channel correlationとspacial correlationが完全に分離可能という仮説が必要1。
以下豆知識
- Xception はeXtreme inCEPTIONから来ている
- Xceptionは、いわゆるdepthwise separable convolutionにほぼ同じ
- チャンネルごとに独立した空間方向convolutionとPointwise (1x1) convolutionのセット
- つまり、Depthwise separable conv = spacial conv + pointwise conv
- これとは順番が違う(Xception = pointwise + spacial)のと、間に非線形関数(ReLUとかELU)が挟まれないという違いがある。
- 1つ目の違いはどうでもいい。どうせたくさん積み重ねて使うので
- 2つめは効果ありかも。図10を参照

空間方向のコンボリューションをする前、チャンネルがいくつの独立した部分segmentに分かれているかで分類すると……
- 通常のコンボリューションはすべてのチャンネルが一つになっている
- Inception Moduleは3-4つに分かれている
- Xception Moduleはすべてのチャンネルが独立している
という考察も可能
一番過激なXception仮説に基づいてXception ModelをGoogLeNetと同じくらいのパラメータ数で構築したら圧勝したよ ……というのが今回の理論的バックグラウンド
備考
空間的に分離したコンボリューション (Spacial separable conv) というのもある (1x7conv → 7x1convみたいなの)
- 歴史は長いらしい(2012年の深層学習の勃興以前から計算量の少ない画像処理手法として使われていた。Separable filterなどで調べよ)
- でもCNN的には性能があまり良くないので最近はあまり使われていないとか
Depthwise separable convを使うアイデア自体はMobileNetで提案されていたとか

){kind=link}
){kind=link}
アーキテクチャ

- GoogLeNetとかと違って繰り返しが多いのでプログラムするのも簡単
結果
- ImageNetで辛勝

- JFT Datasetで圧勝

- Inception V3はImageNetに強いのかも?
- 対ImageNetで作られたInception V3はアーキテクチャ自体がImageNetにOverfitしている?
パフォーマンス

パラメータ数的には互角だが、速さ的には負けた……
負けてしまった理由は、depthwise convolutionの計算の効率が通常のconvに比べて悪いからと思われる。CUDNNとかが最適化されれば同等〜より高速になれるかも3
Residual connectionの効果

- ありそう
- 最終的な結果ももちろん違うが、それに加えて、収束もより早くなっている。
- 論文では述べられていないが、Non-residualだと最初のあたりでろくに予測できていない。これは逆伝播を効率的に飛ばすresidual connectionの効果の一つ。
- ただし、OptimizerなどのハイパラをNon-residualに対しては調整してないのでちょっとハンデになってはいる。
- 別にdepthwise convを使ったモデルにresidualが必須というわけではもちろんない
- convをdepthwiseで置き換えたVGGライクなモデルでも、JFTデータセットに対してはInception V3に勝利
非線形関数を挟むか
GoogLeNetだと挟んだほうが性能が上がったらしい……
が、今回は挟むと下がった
- 中間出力のチャンネル深さによるのかもしれないと考察している
- GoogLeNetだと16~チャンネルあった

- Xceptionは1チャンネル
- Xception仮説に基づいているので
- そのため非線形関数を用いることがチャンネル間の情報を「うまく混ぜる」ことよりむしろ情報を落としてしまうことに繋がり有害なのではないか(今回はそもそも1チャンネルなので混ぜない)
展望
- Xception仮説が完全に正しいかはわからない
- InceptionとXceptionの間にもっといいモデルがあるかもしれない
結論
Inception Moduleは、アーキテクチャ探索を簡単にするために導入されたモデルだったが、それを「チャンネル方向と空間方向のコンボリューションの分離」という解釈のもと考察した。 その考察をもとに、もっと過激に『完全分離可能』を仮定したモデルを作ってXceptionと名付けた。 depthwise convolutionはInception Moduleと同じような性質(depth/space separation)を持つしプログラムしやすいからこれからますます使われそう(実際よく使われている)
この記事はMETRICAの内部勉強会用の資料を改稿して作りました
Binary Neural Network その3:「XNOR-Net」を読みました
インターンの中村です。
今回はXNOR-Netという論文を読んだので解説します。
またXNOR-Netの関連論文も解説していますので、よかったら見てください。
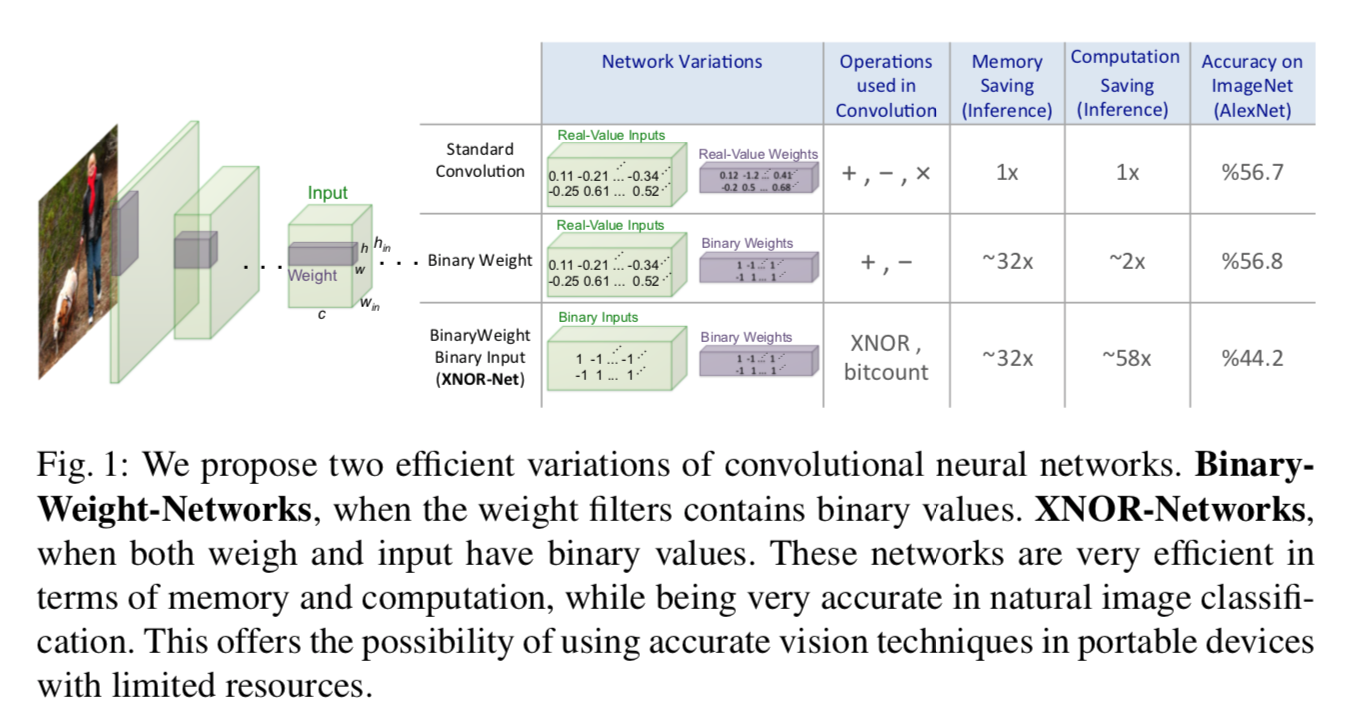
この論文ではBinary Neural Networkの 係数(scaling factor) を計算することにより、本来のニューラルネットワークに層の出力結果をより近づけ、性能を向上させることを提案しています。
新規性
- 重みがbinarizeされたBWN(Binary Weight Network)、及び、入力・重みの両方がbinarizeされたXNOR-Netを提案
- これらでは係数scaling factorを計算する
- 計算が早い
- 性能も良い
- ブロックの順番を入れ替えることにより性能が向上することなどの考察
1.重みがBinarizeされたBWN
画像$\mathbf{I}$が入力された時、フィルタ$\mathbf{W}$をバイナリフィルタ$\mathbf{B}$, スカラーである係数$\alpha$で近似します。
すなわち
$\mathbf{I} * \mathbf{W} \approx(\mathbf{I} \oplus \mathbf{B}) \alpha$
(ただし、$\oplus$は2値化された内積)
この時、目的関数は
 であり、これを偏微分をつかって解くと
であり、これを偏微分をつかって解くと

になります。それぞれ重みの符号、重みの絶対値の平均値となっており、直感的にも納得の行きやすい数字ですね。 これによって近似されたWを$\widetilde{W}$と呼びます。すなわち$\widetilde{W}=\alpha^{*} \mathbf{B}^{*}$です。 これを使ったNNを構築します。順伝播は$\mathbf{I} \oplus \widetilde{W}$とすれば良く、逆伝播はこれにchain ruleと積の微分公式を適用すれば

になるとわかります(ただし、2つめの式はこれ以前の論文で実験的に得られたテクニックに基づいているものであり非自明です)。これを使って計算していけばいいです。フィルタの計算が積ではなく足し引きで計算できるので、計算が早くなります。
これを発展させたXNOR-Netを考えます。
2. 重みも入力もBinarizeされたXNOR-Net
$\mathbf{I}$のうちコンボリューションされる範囲の入力$\mathbf{X}$、フィルタ$\mathbf{W}$が与えられた時(つまり$\mathbf{X}$と$\mathbf{W}$は同じ大きさです)、 $\mathbf{X}^{\top} \mathbf{W} \approx \beta \mathbf{H}^{\top} \alpha \mathbf{B}$ で近似します。すなわち、
$$ \alpha^{*}, \mathbf{B}^{*}, \beta^{*}, \mathbf{H} *=\underset{\alpha, \mathbf{B}, \beta, \mathbf{H}}{\operatorname{argmin}}|\mathbf{X} \odot \mathbf{W}-\beta \alpha \mathbf{H} \odot \mathbf{B}| $$
のような最適化問題と考えることができます。$\alpha$はコンボリューションフィルタ$\mathbf{W}$に対して単一の値ですが、$\beta$はウィンドウごと(コンボリューションする場所ごと)に異なる値だということに注意してください。 この問題は
$$ \mathbf{Y}_{i}=\mathbf{X}_{i} \mathbf{W}_{i},\mathbf{C} \in{+1,-1}^{n} \ \ \text{s.t. }\ \mathbf{C}_{i}=\mathbf{H}_{i} \mathbf{B}_{i} $$
および
$$ \gamma \in \mathbb{R}^{+} \ \text {s.t.}\ \gamma=\beta \alpha $$
とおくと
$$ \gamma^{*}, \mathbf{C}^{*}=\underset{\gamma, \mathbf{C}}{\operatorname{argmin}}|\mathbf{Y}-\gamma \mathbf{C}| $$
と書くことができ、BWNと同じ最適化問題と考えられるので
$$ \mathbf{C}^{*}=\operatorname{sign}(\mathbf{Y})=\operatorname{sign}(\mathbf{X}) \odot \operatorname{sign}(\mathbf{W})=\mathbf{H}^{*} \odot \mathbf{B}^{*} $$
を得、また自然な近似により
$$
\left(\frac{1}{n}|\mathbf{X}|_{\ell 1}\right)\left(\frac{1}{n}|\mathbf{W}|_{\ell 1}\right)\approx\beta^{*} \alpha^{*}
$$
を得ます。あとは$\alpha ,\beta$をこれに従って計算すればいいですね。
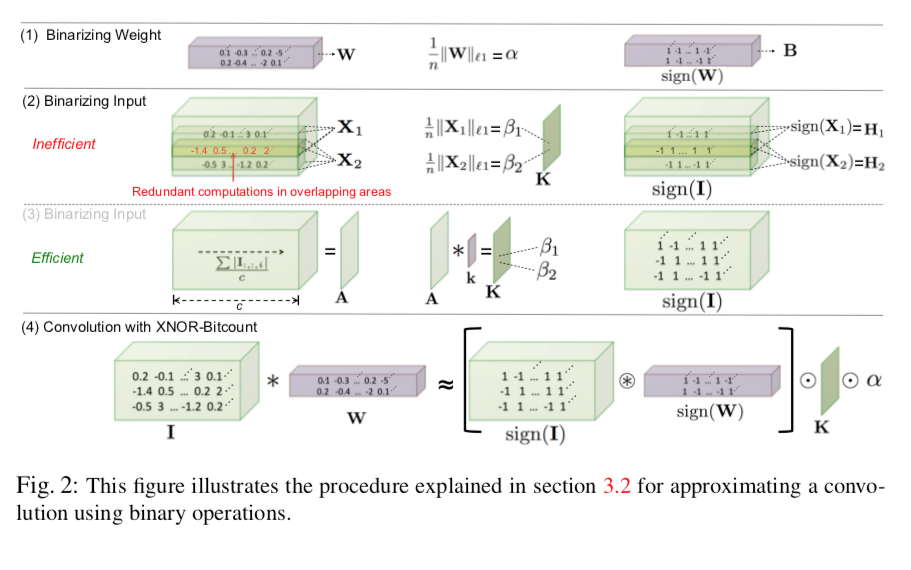
普通に考えると図2(1),(2)のように
- 重みをBinarize
- それに対して最適な$\alpha$を求める
- 入力をbinarize
- 最適な$\beta$をウィンドウそれぞれについて求める
という作業が入りますが、図2(2)ではなく図2(3)のようにすると$\beta$を効率的に求めることができ計算量を減らすことができます。
- Convolution windowごとに$\beta$を求めなければならないので、先にチャンネル平均をメモしておくことで高速化します。競プロ的なテクニックですね。
数式で書くと次のようになります:
$\mathbf{A}=\frac{\sum_i\left|\mathbf{I}_{:, :, i}\right|}{c}$(チャンネル平均を取る)
$\mathbf{K}=\mathbf{A} * \mathbf{k}\ \mathrm {\ where\ } \forall\ i,j\quad\mathbf{k}_{i j}=\frac{1}{w \times h}$
この結果、$\mathbf{K}$は求めたい$\beta$の行列になっている、よって

として近似を得る(ただし、$\otimes$はXNOR積)
パフォーマンス比較
XNOR-Netは文字通り重みと入力のXNOR(一致するなら$1$、一致しないなら$-1$)を取るだけなので、コンボリューション部の計算が非常に速いです。理論上、CPUはきちんと実装すれば1クロックで64bitのXNOR計算ができるので $S=\frac{c N_{\mathbf{W}} N_{\mathbf{I}}}{\frac{1}{64} c N_{\mathbf{W}} N_{\mathbf{I}}+N_{\mathbf{I}}}=\frac{64 c N_{\mathbf{W}}}{c N_{\mathbf{W}}+64}$
- ただし、$c$:チャンネル数,$N_{\mathbf{W}}$:ウィンドウの大きさ、$N_{\mathbf{I}}$:入力画像の大きさ
倍になります。これは、例えばResNetの多くのコンボリューションにおけるパラメータ($c=256,N_{\mathbf{I}}=14^{2}, N_{\mathbf{W}}=3^{2}$)で62.27倍です。著者らはオーバーヘッドにより実際は58倍程度の性能を得たようです。
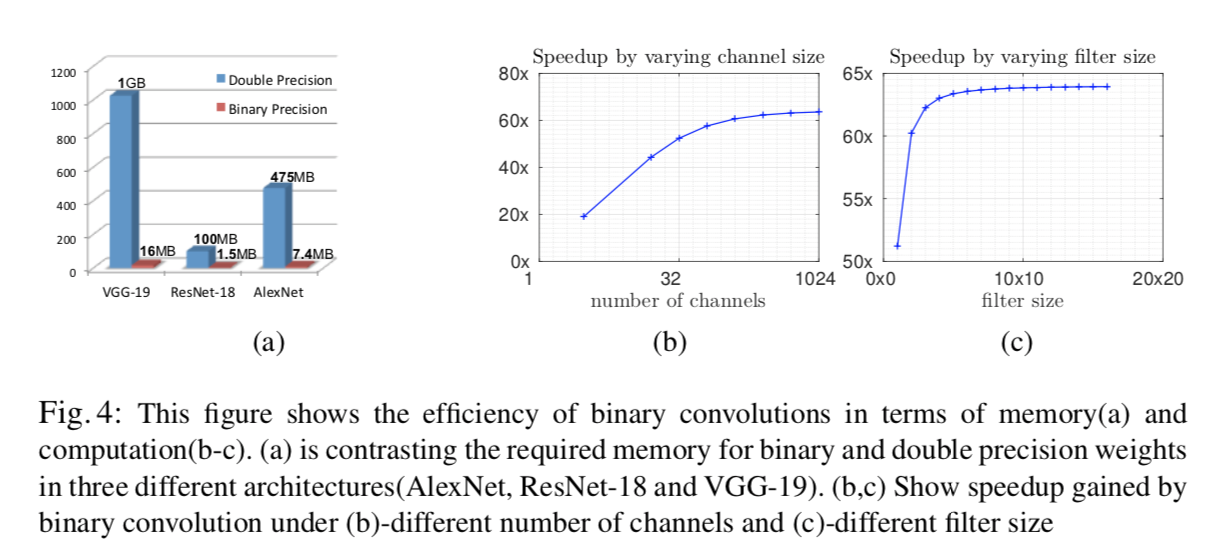
メモリサイズも非常に小さくなります。図4にわかりやすくまとまっているので参照してください。
性能比較
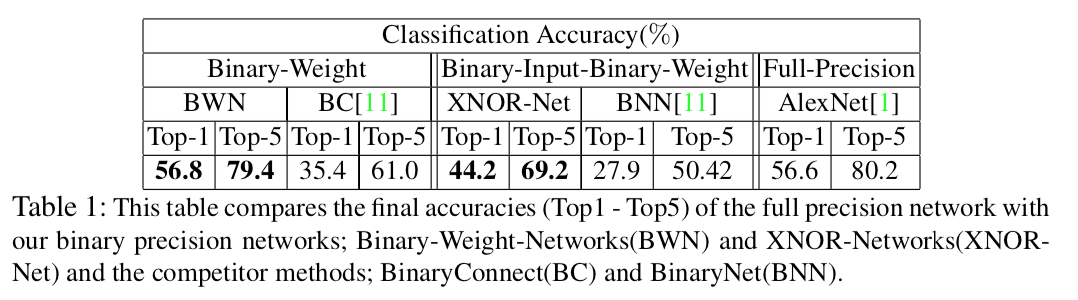
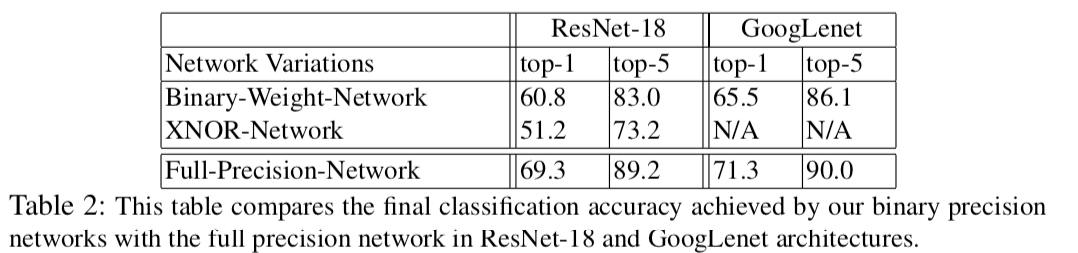
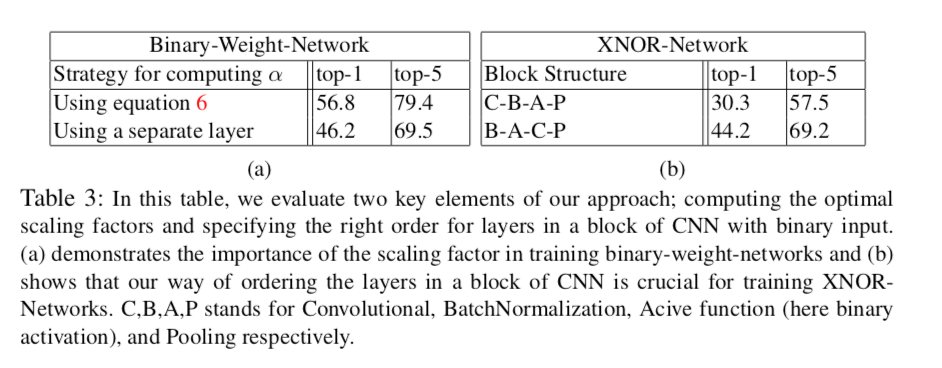
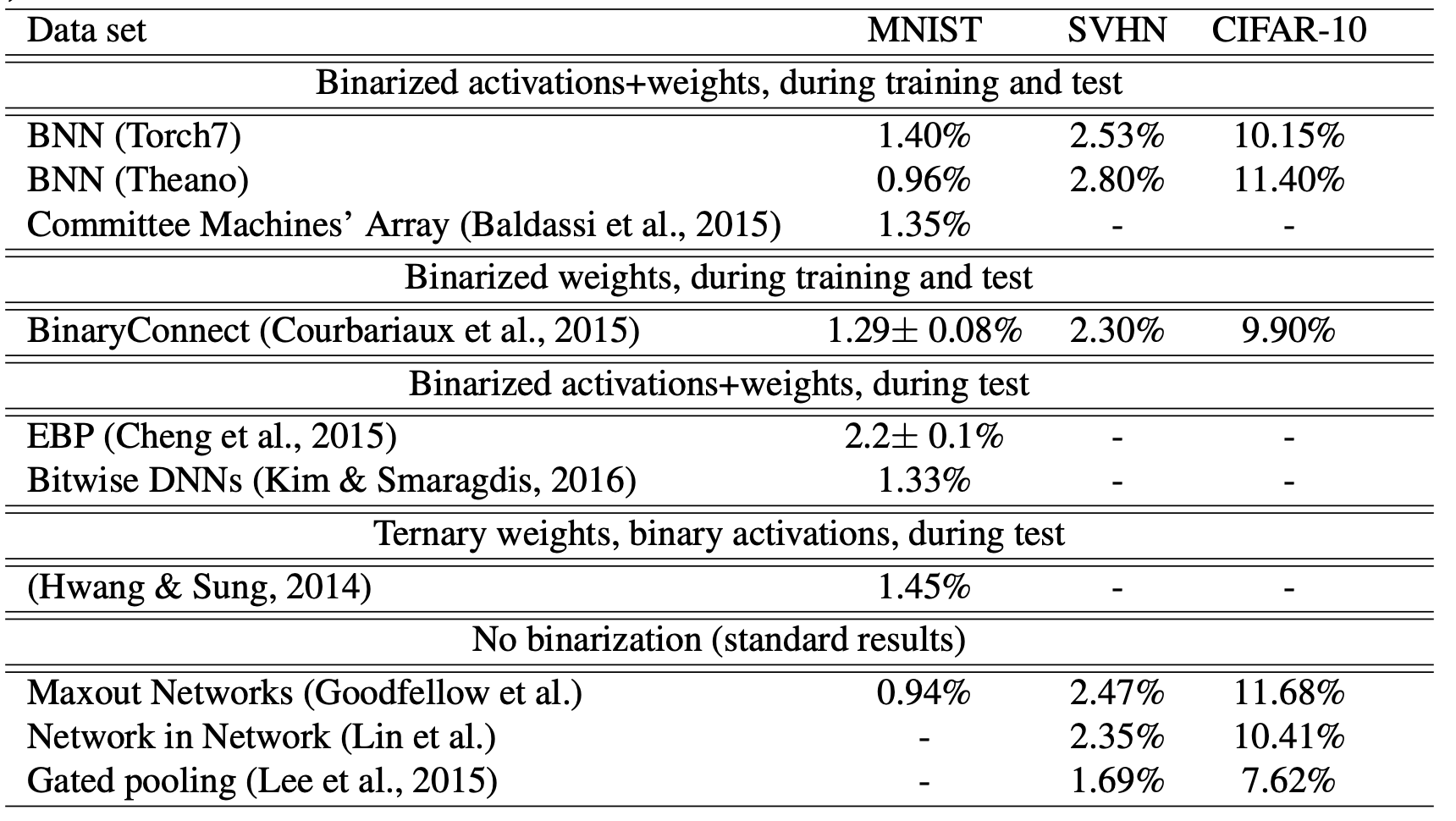
表1,2に示すように、提案手法であるBWN,XNOR-NetはこれまでのBinarize手法に比べ高い性能を示しています。
$\alpha$をバイアス項なしのAffine Layerと捉え(いわゆる$y=Ax+b$で$A$をスカラー、$b$をゼロと考えるわけですね)、独立した層として訓練することも可能ですが、結果としてはこれをやっても表3(a)に示されるように性能が下がってしまいます。これはパラメータ$\alpha$を$|\mathbf{W}|$の平均として計算するという方法が最適であることを示唆しているでしょう。
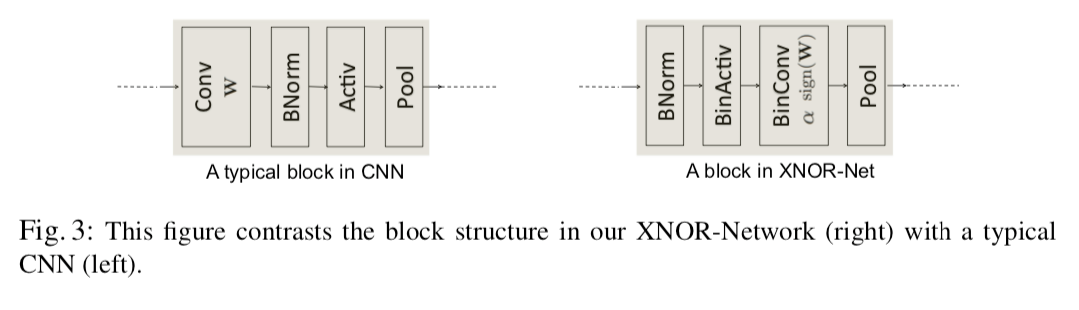 また、表3(b)では図3のように層(ブロック)を入れ替えると性能が向上するということも示されています。この順番のほうが性能が良くなる理由として、
また、表3(b)では図3のように層(ブロック)を入れ替えると性能が向上するということも示されています。この順番のほうが性能が良くなる理由として、
- Binarizeした直後にMax-Poolingをするとほとんどの要素が1となり情報が大量に失われてしまう
- BatchNormをすると平均が0になるので、その直後に0-thresholdであるBinarizeをするとそれによる誤差が少なくなる
事が考察されています。
今後の展望
実際にやってはいないようですが、以上の手法はk-bitの量子化に対しても容易に拡張できるとされています。$[\cdot]$を床関数として、入力$x\in[-1,1]$に対し
$$ q_{k}(x)=2\left(\frac{\left[\left(2^{k}-1\right)\left(\frac{x+1}{2}\right)\right]}{2^{k}-1}-\frac{1}{2}\right) $$ とするわけですね。
まとめ
この論文ではscaling factorと呼ばれる係数を2値化ニューラルネットに導入し、それらに対する理論的な考察によってその効率的な計算方法を与えることにより、良い時間・空間計算量、end-to-endで訓練することができるという性質を保ちつつ性能を大きく向上させました。 理論的考察のところはかなりバッサリ省略しながら書いたので、細かいところが気になった人はぜひ論文にあたってみてください。
なお、本記事はMETRICAの勉強会向けに作った資料を修正したものです。
Binary Neural Network その2:「Binarized Neural Networks」を読みました
この記事は6/15に開催されたMETRICAエンジニア勉強会の発表資料です。
今回は参加者の西本くんがBinary Neurarl Networkについて発表してくれました。
Binarized Neural Networksの関連のある論文としてBinary Connectも解説してくれています。
背景
- Deep Learningの学習はエネルギー消費の多いGPUを使うことがほとんど。
- 近年low-powerなデバイス上でDeepLearningの計算を行うための研究も盛んに行われている。
Binarized Neural Networks (BNNs)
著者は重みだけでなく活性も2値化したBinarized Neural Networkを提案した。
これは、学習時は2値化された重みと活性を使って勾配計算し、2値化された重みと活性を用いて推論するようなNeural Networkのことである。
重みの2値化
決定的(Deterministic)な方法と、確率的(Stochastic)な方法がある。
- Deterministicな方法:

- Stochasticな方法


$\sigma(x)$はハードシグモイド関数である。 Stochasticな2値化は乱数発生器を必要とするので実装がやや困難である。 この論文においては、活性化に対してはいくつかの実験で学習時にStochastiな2値化を行うが、それ以外は専らDeterministicな2値化を行う。

学習時

勾配の計算と蓄積
- 誤差関数の勾配を計算する際は2値化された重みと活性を用いるが、勾配が蓄積され更新される重みは、高精度の実数値のままにしておく。SGDによりうまく重みの更新が行われるためには、更新される重みは高精度実数である必要があるからである。
- 重みと活性の2値化をノイズ付加とみなすことができる。DropOut, DropConnectの研究からわかるように、勾配計算の際に重みや活性にノイズを加えることは汎化性能向上に繋がり、正則化として機能する。特にBNNsは、勾配計算の際に、ランダムに活性の半分を0にするのではなく、活性と重みの両方を2値化するという点で、DropOutの変種と見ることができる。
実数の重み$W$の更新の際、$Update()$ (ADAM or Shift Based AdaMax) の結果を$ Clip() $ 関数で$-1 \sim 1$に押し込めている。
Batch Normalizationについて
Batch Normalizationは学習を早め、重みのスケールの影響を減らすが、都度標準偏差を計算して割る必要があり、掛け算の操作がたくさん必要になる。
代わりに、shift-based batch normalization(SBN)というテクニックを使った。
掛ける数/割る数をそれより小さい整数のうちでもっとも2の冪小数に近い数で近似して、$\ll\gg$(both left and right binary shift)することで、掛け算の操作を回避しつつ、通常のBatch Normalizationと同様の性能を実現した。
重み$\mathbf{w}$とバッチ正規化のパラメータ$\theta$のUpdateについて
ADAMも重みのスケールの影響を減らしてくれるが、多くの掛け算の操作を必要とする。
Algorithm4で述べられているようなshift-based AdaMaxという方法を用いることで、掛け算の操作を減らしつつ、ADAMと同様の性能を実現した。

sign関数の微分が0になる問題
$$ q=sign(r) $$
において、$ \frac{\partial C}{\partial q} $ の推定値$g_q$が既知のとき、
$ \frac{\partial C}{\partial r} $ の推定値$g_r$を以下の式によって推定する。
$$ g_r = g_q1_{|r|\leq1}$$
このような推定では、$|r|$が小さいは、勾配情報がそのまま保存される。(straight-through estimator) 大きいときは勾配は0となるが、このようにしないと、モデルのパフォーマンスは悪化する。
$$1_{|r|\leq1}$$
は、
$$Htanh(x) = Clip(x, -1, 1) = max(-1, min(1, x))$$
の導関数でもある。つまり、上の推定は、勾配計算の都合上$sign(x)$を$Htanh(x)$とみなしていると解釈することができる。
予測時

1層目の処理
1層目の入力だけbinaryではないが、著者によると大きな問題ではない。
というのも、連続量をm bitの不動点として扱うことができ、
$$ s = x \cdot w^{b} $$
$$ s = \sum_{n=1}^{8} 2^{n-1} (x^n \cdot w^b) $$
により1層目の重みと入力の積が計算可能だからである。
XnorDotProduct
XNOR Table
| x | y | z |
|---|---|---|
| -1 | -1 | 1 |
| -1 | 1 | -1 |
| 1 | -1 | -1 |
| 1 | 1 | 1 |
$ x \times y = z $の関係にあることがわかる。
内積計算は掛け算して足すという操作に相当する。掛け算の部分をbit毎にXNORゲートで計算するような内積計算を本論文ではXNORDotProductと読んでいる。
結果
実験の条件を整理
| Torch7 | Theano | |
|---|---|---|
| Activations | Stochastically binarized | Determinasitically binarized |
| Batch Normalization | shift-based BN | vanilla BN |
| Learning rule | shift-based AdaMax | ADAM |
モデルの汎化性能
- Binary Connect よりも性能は落ちる。
- Committee Machines’ Array (Baldassi et al., 2015)は畳み込み層を持つモデル対応していない。
- 学習、推論が低電力で行えることと汎化性能のトレードオフがある。
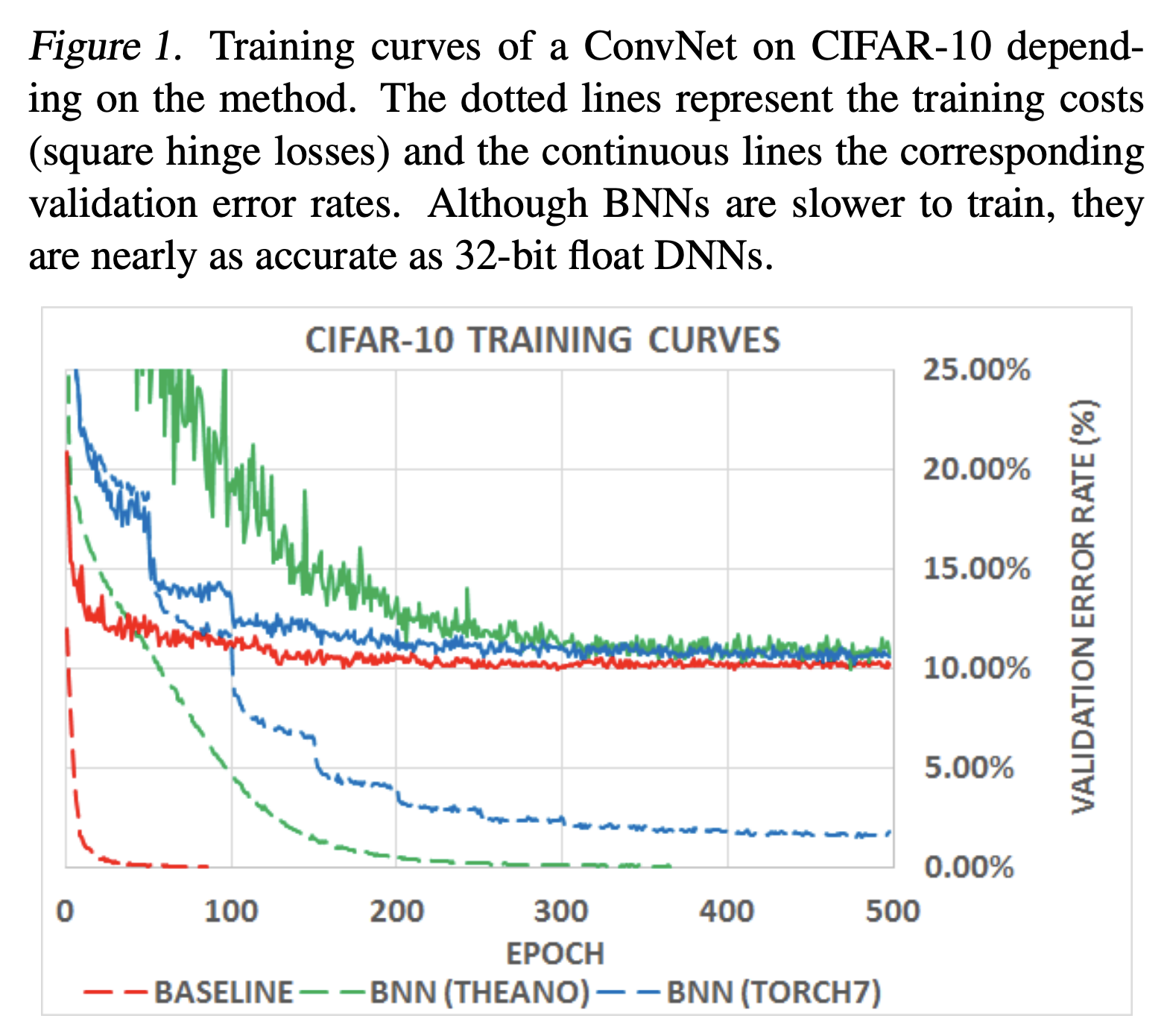
学習曲線
- 学習にかかる時間はBNNsの方が遅くなっている
- shift-basedのBNNの方がそうでないBNNsよりも学習が遅い。
- アーキテクチャの問題?
- 最終的には通常のDNNsに近い値に収束する。
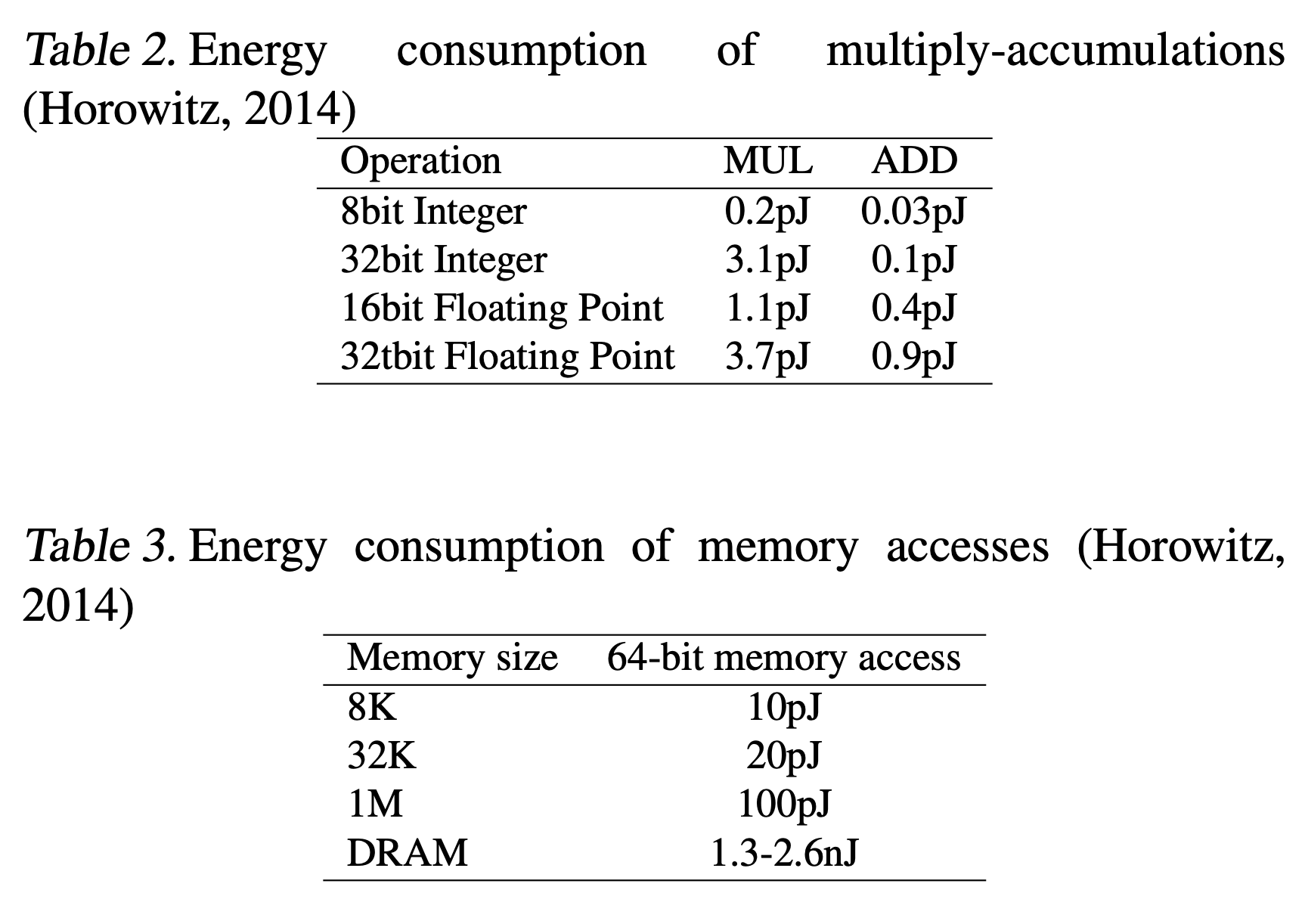
電力効率
- BNNsは特に、train時の順伝播計算と、推論時のエネルギー効率が大変良く、メモリサイズとアクセスを減らすことができる。
- 活性の2値化は、特に畳み込み層を持つモデルで計算を効率化できる。
- 重みの自由度よりもユニットの方がずっと多いため。
- 下の表から、積-和計算やメモリアクセスを減らすことの恩恵の大きさがわかる。
- 通常のDNNsでは32bitの実数の積を求め総和をとっていたが、それがBNNsでは1bitでできる。
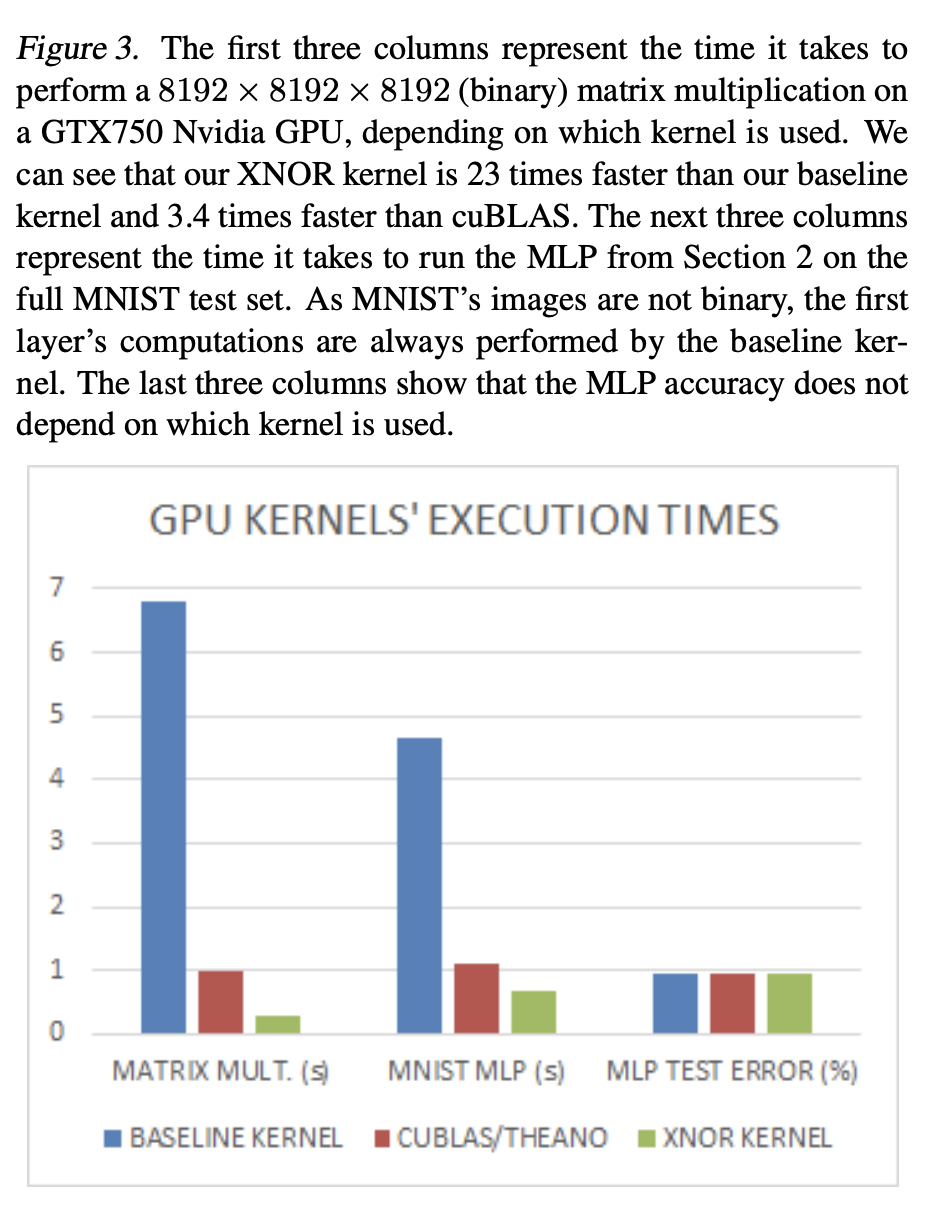
BNNsに最適化したGPUと通常のGPUの比較
- MLP(BNNs)によるMNISTの推論が、性能を保ったままふつうのKernelよりも7倍高速化できた。
結論と展望
- Trainの逆伝播、パラメータ更新のところで最適化の余地がある。
- 特に、パラメータ更新を実数で持たなければならない点がボトルネック。
- 他のbentchmarkの結果を増やす。
Binary Neural Network その1:「BinaryConnect」を読みました
この記事は6/8に開催されたMETRICAエンジニア勉強会の発表資料です。
今回は参加者の西本くんがBinaryConnectについて発表してくれました。
背景
近年、計算可能性が新しいアルゴリズム開発のネックになる場面が散見されるようになった。また、実際の応用において、GPUよりもパワーの弱いデバイスにDeepLearningのモデルを載せたいというニーズも出てきた。そこで、DeepLearningの学習、予測の際の計算高速化に関心が集まっている。
モデルの重みを2値化することで、積和操作を単なる和に置き換える事ができる。乗算器は、Deep Learning の計算において、メモリとパワーを大変多く消費するので、これは利点が大きい。
著者は、重みの2値化によるDeepLearningの計算高速化の手法の1つとして、BinaryConnect(BC)を提案した。
BinaryConnect
重みの2値化
決定的(Deterministic)な方法と、確率的(Stochastic)な方法がある。
Deterministicな方法:

Stochasticな方法


( \sigma(x))はハードシグモイド関数である。ソフトなシグモイド関数を用いなかったのは、計算量を減らすためである。
学習時
- 順伝播、逆伝播の際は2値化された重みを用いる。
- 勾配が蓄積されて更新される重みは、高精度の実数値のままにしておく。
Binary ConnectとSGDの互換性
重みの2値化をノイズとみなすと。noisyで微小なステップで重みが更新され、更新が進むにつれてノイズは相殺される。よってBinarry Connect はSGDにより学習を行うことができる事がわかる。うまく更新が行われるためには、更新される重みは高精度実数である必要がある。

予測時
次の3通りの方法のうち、どの方法で予測を行うのがが合理的な方法だろうか?
- 2値化された重み$( w_b )$を用いて予測する。
- 高精度実数の重み$(w)$を用いて予測する。
- アンサンブル法で予測する。
Det.では、2値化された重み$ ( w_b )$ を用いて予測する。 こうすることで、予測の際の乗算を取り除くことができる。
Stoc.では、高精度実数の重み $( w )$ を用いて予測する。
これは、学習時にノイズを加え、予測時はノイズを除くというDropoutの考え方に通じるものがある。
結果
Binary Connect を用いることで、学習時の乗算を1/3に減らし、学習時間が約3倍短くなった。 特にDeterministicなBCでは、予測時の乗算がすべて取り除かれて、必要なメモリが16倍以上少なくなった。
また、DropOut同様、BinaryConnectは正則化として作用し、汎化性能向上に寄与することもわかった。
重みの離散化は、重みへのノイズ付与とみなせる。重みにノイズを加えることが正則化として作用し、モデルの汎化性能を向上させる。
これは、伝播計算の際に半数の重みを0にするDrop Connectと似ている。
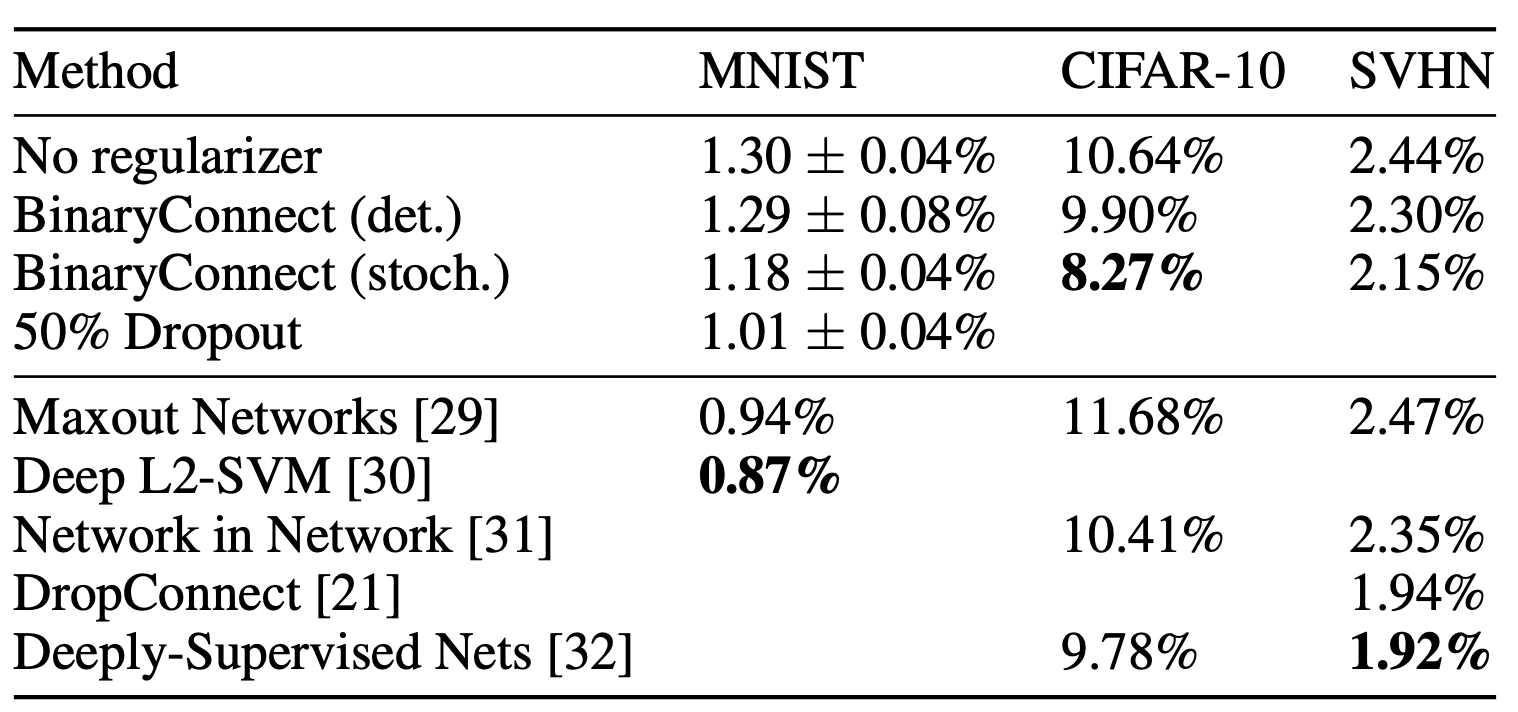
類似研究との比較
重みを2値化したDeep Neural Networkに関する他の研究と比較して、本研究は以下の特徴がある。
- 既存研究では、重みの更新にExpectation Back Propagetion (EBP) を用いていたが、本研究ではBAck Propagation (BP)を行った。
- CNNの学習に成功した。
今後
- 他のモデルやデータセットで性能を試してみる
- 重みの更新の計算を必要なくして、学習時の掛け算を完全に除去したい