SSDの改良モデル「RefineDet」を読んでみました
インターンの中村です。
今回はRefDetを読んだので解説していきます。
正しい論文タイトルは"Single-Shot Refinement Neural Network for Object Detection"。 arxiv
Object Detectionには2-stageと1-stage(Single Shotとも)の2つのアプローチがあり、一般に2-stageは精度が高いが遅く、1-stageは速いが精度が微妙。なので2つのメリットを組み合わせたモデルを提案した
既存研究の状況

(1-stage methodであるSSDのアーキテクチャ)

(2-stage methodであるFaster R-CNNのアーキテクチャ)
2-stage methodsは次のようなメリットがある:
- class imbalanceを是正するサンプリングができる(ため、classifierの訓練がよりうまくできる)
- ボックスのパラメータを2段階に渡って調整できる
- 2段階に渡る特徴量でボックスを記述できる
- 上図のFaster R-CNNでは、最初のRegion Proposal NetworkがProposal, すなわちAnchor1か否かを出力し、second stageでclassificationをする。この発想がこの論文にも用いられている
この論文のcontribution
この論文のアーキテクチャはSSDの発展版と言える部分がとても多いので、かぶっている部分についてはかなり省略している。SSDを知らない人は以下を読む前に予習しておいたほうが良いだろう2。

- ARMとODMという2つのモジュールからなる新モデルの提案
- すべてConv/Deconv/Addなどでひとつなぎに構成されている1-stage method
- 1-stageの効率と2-stageの性能を併せ持つ
- TCBを使ってそれらの間をつなぎ、ARMの特徴量をODMに渡す
- 正確な物体の位置&大きさ、クラスをODMに求めさせる
- Pascal VOC 2007/2012, MS COCOでSOTA
それぞれのモジュールの解説
ARM
SSDと結構似ているので省略する
細かい違いとしては、
- SSDの入力画像サイズは300/512だが、RefineDetでは320/512
- こちらのほうがstrideでサイズが半々になった時に扱いやすいし、賢い変更だと思う
- BackboneにResNet-101を使ったりもしている
- 推論速度を上げるため、逆にSSDの下位互換になっているところもある
TCB

ARMの特徴量を取ってきて、より深いレイヤのものと足し合わせる
- TCBに渡すのは「ARMの出力した結果」=「箱のサイズ・クラスに関する予測」ではなく、ARMへの入力である。
- すなわち、概観図における箱はコンボリューションではなく中間特徴量を表している。
- サイズが合わないのでDeconvで倍にする
- 大きいスケールのコンテクストを統合する効果があると考えられる
ODM
これこそSSDとまったく同じなので省略
予測の出し方
ARMは、それぞれのanchorに対して
- その箱の中に物体はあるか否か(dim=1)
- Anchorと比べた位置・大きさの修正(dim=4)
を出力し、ODMは
- 物体のクラス(dim=class)
- ARMの予測と比べた位置・大きさの修正(dim=4)
を出力する
訓練
クラス間inbalanceの是正
- ARMのconfidence出力があまりに低い($\leq 0.01$など)ものは、ODMに渡さない
- あまりに明白すぎるbackgroundは渡さないということ
- Hard negative samples3のみを渡す、という言い方をする
- これは推論時も同じ
- あまりに明白すぎるbackgroundは渡さないということ
- 更に、それでもnegative sampleは非常に多いので、訓練時はそのうちからランダムに選び、$\mathrm{neg:pos} = 3:1$になるようにする
- SSDと同じ
Anchor Boxのマッチング
最もjaccard overlapの良いboxとマッチし、そのあとoverlapが0.5を超えているもの全てとマッチする。SSDと同じ
損失関数
損失は

それぞれの項は
- $g_i^*$: Anchorの位置・大きさの正解
- $l_i^*$: Anchorの正解クラス(クラスがbackground、すなわち何でもないなら0、それ以外なら1, 2, ...)
- $p_i$: ARMの予測したあるか否かのbinary confidence
- $x_i$: ARMの予測した位置・大きさ
- $c_i$: ODMの予測したクラス
- $t_i$: ODMの予測した位置・大きさ
- $[cond]$: $cond$が満たされるなら1, そうでないなら0
ロス関数は
したがって、それぞれの損失は
- ARMが予測したbinary confidenceが合っているか
- (実際にそこにanchorがあったとき)ARMの予測した位置は正しいか
- ODMの予測したclassが合っているか
- ODMの(ARMの予測を修正することによって)予測した位置は正しいか
を見ていることになる
推論
上に述べたように、推論時はARMでしきい値に満たなかったものを取り除き、ODMがそこからconfidentなAnchor TOP400を取り出す。 最後にNMS(SSDと同じなので省略)をjaccard overlapしきい値0.45でかけ、トップ200を取り出して最終的な推論結果とする(ここはSSDもおなじ)
結果比較

- Real Time Inferenceなのにabove 80% mAP!世界初!どや
- SSD300, YOLOはわずかにRefineDet320より速いが、性能でかなり勝ってる
- 個人的には$AP_S$の性能がいいのが注目ポイント
Ablation Study
次の3つの変更を順に行ってみて、性能がどう変わったかを調べた
Negative Anchor Filtering
- 訓練・推論時ともにしきい値を1に→どんな負例もすべてODMに送られる
Two-Step Cascaded Regression
- ARMからの修正ではなく、ODMのみで場所を調整させる
Transfer Connection Block
結果

- Negative Anchor Filteringはちょっと効いてる
- ARMで不要なものを取り除くのはとくに訓練時に効果がありそう
- Two-step cascaded位置調整が実は一番効いてて面白い
- No Transfer Connection BlcokなしモデルはSSD300のmAP=77.2にすら負けてる
MS COCOを使った事前訓練
- Pascal VOCの物体クラスはMS COCOに含まれているので、パラメータを一部取り除くだけで直接fine tuningできる!うれしいね
- 性能は更に上がる⤴

- RefineDet512+の記録はVOC2012 LBで5位
- One-stage methodとしては1位
- ほかのtwo-stage methodもResNet-101やResNeXt-101のようなもっと深いネットやアンサンブルをしている
- どやその2
この記事はMETRICAの内部勉強会用の資料を改稿して作りました
-
同僚のYuki03759の記事が補完的な内容になっているので、これを読むのもありである↩
-
「判定の難しい負サンプル」の意↩
1stage物体検出モデル「SSD: Single Shot MultiBox Detector」を読んでみました
SSDとは

- 単一ディープニューラルネットワークを使って画像の中の物体を検出する方法
- 論文ではVGG16にExtra Feature Layersという畳み込み層を加え、物体検出を可能にした
- 予測時にカテゴリスコアの算出とデフォルトボックスの調整を行う
Contribution
- これまでの最先端であるYOLOを超える速度と性能を持つ物体検出方法(SSD)の提案
- 小さな畳み込みフィルターを使うことで、デフォルトバウンディングボックスのカテゴリスコアとボックスのオフセットを予測させた
- 異なるスケールの特徴マップから異なるスケールの予想を作り出し、アスペクト比によって明示的に分割した
- これらのデザインによって低解像度の画像であっても、シンプルな End-to-End の訓練と高い精度につながり、スピードと精度のトレードオフを解消した
- 様々な入力サイズをPSCAL VOC COCO, ILSVRCで検証して、最先端モデルと比較した。
1. Introduction
これまでの物体検出との比較
- 今までの手法
- SSD
- 初のディープニューラルネットワークベースの検出器
- ピクセルや特徴を再サンプル必要がない
- バウンディングボックスの採用と再サンプル工程を取り除きをしたため、従来より早い
2. The Single Shot Detector (SSD)
SSDのフレームワーク

- 入力画像と正解ボックスが必要
- 畳み込みによって、異なるいくつかの(4つくらいの)アスペクト比のデフォルトボックスと正解ボックスを異なるスケール(eg. 4x4 や 8x8)で評価する
- マッチしたデフォルトボックスは正、しなかったものは負として扱われる
2.1 モデル
2.2 訓練
マッチング戦略
- デフォルトボックスはjaccard係数が0.5以上であるものを正解としている

損失関数 = 確信度誤差関数 + 位置特定誤差

$$ x_{i, j}^{p} = \left\{ 1, 0\right\} $$ $x$: カテゴリpにおいて、i番目のデフォルトボックスとj番目の正解ボックスのマッチ度を示すもの $N$: マッチしたディフォルトボックスの数 $l$: 予測されたボックス $g$: 正解ボックス $c$: デフォルトボックスの座標のオフセット ((cx, cy) のように書く) $d$: ディフォルトバウンディングボックス $ω$: 幅 $h$: 高さ $α$: ハイパーパラメーター (実験では1とした)
確信度誤差関数

位置特定誤差関数
$$ L_{loc}(x,l,g) = \sumN_{i \in Pos}\sum_{m \in {cx, cy, w, h}} x^k_{ij} {\rm smooth_{L1}}(l^m_i-\hat{g}^m_j) $$

正規化
$$ \hat{g}^{cx}_j = (g^{cx}_j - d^{cx}_i) / d^{w}_i $$
$$ \hat{g}^{cy}_j = (g^{cy}_j - d^{cy}_i) / d^{h}_i $$
$$ \hat{g}^{w}_j = \log(g^{w}_j / d^{w}_i) $$
$$ \hat{g}^{h}_j = \log(g^{h}_j / d^{h}_i) $$
デフォルトボックスのスケールとアスペクト比の選び方
デフォルトボックスのアスペクト比の計算
- k番目の特徴マップのスケール $s_k$

- k番目の特徴マップのスケール $s_k$
高さと幅
$ a_r $ : アスペクト比{1, 2, 3, 1/2, 1/2}
$$ h_k^a = \frac{s_k}{\sqrt{a_r}} $$
$$ ω_k^a = s_k(\sqrt{a_r}) $$
- デフォルトボックスの中心
$$ (\frac{i+0.5}{|f_k|}, \frac{j+0.5}{|f_k|}) $$
$|f_k|$ : k番目の特徴マップのサイズ
3. 検証

- ILSVRC CLS-LOCで事前に訓練されたVGG16をベースに検証が行われた
3.1 性能比較 1 - PASCAL VOC2007
PASCAL VOC 2007
PASCAL VOC 2007 テスト結果

- 全体平均的にSSDの精度が高いことがわかる
- 最高で81.6% mAPを記録
- 入力画像は大きい方が良い
PASCAL VOC 2007 テストの動物、乗り物、家具の分類
 $Cor$ : 正解
$Loc$ : 位置の間違い
$Sim$ : 似たカテゴリの間違い
$Oth$ : 別の物体との間違い
$BG $ : 背景との間違い
$Cor$ : 正解
$Loc$ : 位置の間違い
$Sim$ : 似たカテゴリの間違い
$Oth$ : 別の物体との間違い
$BG $ : 背景との間違い
発見と課題
- SSDはR-CNNより位置特定誤差が少ない
- カテゴリで多くの取り違えをしてしている
- 複数カテゴリの場所を共有していることが部分的な原因
- 小さな物体ではうまく認識できないことが多い
3.4 性能比較 2 -COCO
COCO
- セマンティックセグメンテーション情報が付加されたデータセット

- COCOの物体は小さい傾向にある
- R-CNNよりも良い結果が出ている
3.7 Inference time

- Fast YOLOは155FPSと出ているが精度が22%ほど低い
- それ以外は速度と精度の両方でより良い結果が出ている
- SSDの計算時間の80%はベースネットワークに使われているため、この速度が改善されればより早いモデルになることができる
DenseNetを高速化した論文「VoVNet」を読んでみました
インターンの中村です。
今回はVoVNetを読んだので解説していきます。
https://arxiv.org/abs/1904.09730
Abstract
正式な論文タイトルは "An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection".
つまり、この論文ではGPU上でリアルタイム実行するときに本当に性能の良いモデルはなにかということを理論的に考察している。
また、考察の結果としてOne-Shot Aggregationというアーキテクチャを提案している。
既存の研究とその問題
DenseNetは出力をすべての後続のレイヤーの出力にconcatする。

ResNetと比べて前のレイヤーの情報を累積・保存できるという点で優れているが、
- 層の深さの2乗に比例してメモリアクセスが増える
- そのままではえげつないペースで入力チャンネル数が増えるので、Dense Block内で1x1 conv (bottleneck layer)→3x3 convという構造にし、チャンネルの増加率を成長率kに減らしている
1
- しかし、それは巨大なテンソルの計算に適したGPUの長所を削る結果になってしまっている
まとめると、DenseNetは理論上のFLOPSは小さいが実際のGPU上ではエネルギー・時間的に非効率的である。
(なお、これらの性質自体はすでに知られていた。例えば……
- ShuffleNet v2はMobileNet v2と同じくらいのFLOPSだがより速く走る
- SqueezeNetのパラメータ数はAlexNetの50分の1だが、エネルギー消費量はむしろ大きい)
→FLOPSやパラメータ数より実用的な測定基準として、FPS[image/sec]とenergy per image[J/image]でこの論文では考える。実際の計算時は

で求めている。$\text{Average Power}$はご存知nvidia-smiで測定する
モデルの効率に対する考察
MAC
メモリアクセスコスト (MAC) は

で表される
- 第一項が画像へのアクセス
- 第二項がフィルターへのアクセス
- 一度アクセスすればキャッシュに保存しておけるとする
パラメータ数に関係なく、たとえば特徴マップ ($hw$) が大きければMACは大きくなり、また計算量も増える
CNNのエネルギー消費の主要な原因はメモリアクセスであり、またメモリアクセスは時間もかかるので計算時間のボトルネックにもなりうる。MACを小さくすることは重要である。
GPU計算効率
上述したように、GPUは巨大なデータテンソルの計算が得意である。 大きなconvの前に1x1を挟んだり、1x1+depthwiseに取り替えることも、一見FLOPSやパラメータ数をへらすが、GPU的にはあまり嬉しくない。
提案手法
DenseNetの問題点まとめ
- DenseNetでは、層が深くなるごとに線形にチャンネルがガンガン増える
- FLOPSあたりに新しく得られる特徴量が少ない
Dense Connectionのおかげで特徴の質は良いが、特徴の量はあまり増やせなくなってしまった
メモリアクセスコストが大きい
GPUの並列計算に対する強さを損なう
- 1x1 convはGPU的にはあまり嬉しくないので

重みの考察

Dense Block3でTransition Layerはあまり中央のレイヤーを使っていない(②)が中央のレイヤーは中央のレイヤー自身をよく使っている(①)。Dense Block1では逆。 →負の相関があり、片方があれば十分ということは、無駄に情報を伝えている?
One-Shot Aggregation
これは無駄なので、最終層でのみconcatする新たなアーキテクチャ(One-Shot Aggregation, OSA)を提案

- これは各コンボリューションに対して$c{i}=c{o}$、MAC最小化条件を満たす
- 上の図にチャンネル数を明記すると以下のようになる:

- Denseblockでは入力チャンネル数と出力チャンネル数がだんだん食い違っていくが、OSAでは常に同じであることがわかる
- 上の図にチャンネル数を明記すると以下のようになる:
- 1x1 convはブロック(OSA Module)の最後にのみ使われ、一気にチャンネルを圧縮する
モデルの詳細な仕様は以下の通り:

- まずStem Stageと呼ばれる初めの層で基本的なConvolutionを行う2
- その次にOSA Moduleを4回積み重ねる
- OSA Moduleの設定が3つの各モデルで異なる
- 例えば27-SlimのStage 2だと、各convが64チャンネル出力するので、最後に$64\times 5=320$チャンネルがconcatenateされ、それを1x1 convで128にまで減らす

また、OSA Module内のconvの回数を最初は12回にしていたが、③に示されるように最後の方のレイヤーの出力は最後の1x1 convであまり使われていない。 これを取り除いてもさして影響はないと思われたので、最終的にひとつのOSA内のconvの数は5回とされた。
実験
VoV vs Dense

- SSD300-MobileNetがベースライン
- PeleeはDenseBlockやprediction blockにResblockを導入した新しい画像認識モデル
結果
- VoV27は同程度のパラメータ数であるDense67に実測値で勝利。
- FLOPS自体も同程度だが、計算効率(Computation Efficiency)が2倍近く良いので結果としてFPSでは圧勝
- エネルギー効率も4.1倍良い
- PeleeはFLOPS的にはこれらより小さいのに、実際の推論速度はDense67並で残念な感じ
- GPU的にはPeleeの特徴であるdense blockの小さい切り分けは嬉しくないのだろう
- 【参考】(a)がDense Layer, (b)がPeleeで使われた2way dense layer

- 中間特徴マップの数も増えてしまうので、メモリアクセスも大きくなってしまう
- MobileNetはメモリー消費量的には小さいのに、エネルギー効率は悪い
- depthwise convがばらばらに (fragmented) メモリアクセスするから効率が悪い
Ablation study on 1x1 conv bottleneck
 3x3 convのあとに逐一bottleneck layer(1x1 conv)を挟んだら、FLOPSもパラメータ数も減ったけど実際の実行時間とかは伸びてしまったよ😢という図
「1x1 convはリアルタイム推論にとって嬉しくない」という仮説を交絡因子を減らして示した対照実験と言える
もちろん精度も微減😢
3x3 convのあとに逐一bottleneck layer(1x1 conv)を挟んだら、FLOPSもパラメータ数も減ったけど実際の実行時間とかは伸びてしまったよ😢という図
「1x1 convはリアルタイム推論にとって嬉しくない」という仮説を交絡因子を減らして示した対照実験と言える
もちろん精度も微減😢
RefineDetにいろいろなものを載せてみる

結果
- DenseNet-201(k=32)がDenseNet-161(k=48)よりFLOPSは少ないのに遅い
- 同じVoVNetでも、メモリフットプリントが少ないもののほうがエネルギー効率はいい
- 小さい物体の検出にはVoVNet/DenseNetが強い
- concatによる特徴表現の集積が効いていると思われる
Kerasによる実装例
DenseNetと同じく実装は非常に簡単。Classifierとして軽く訓練してみたが、DenseNetより速くて性能も良い感じだ。
次回は、これを用いて訓練スピードなどを定量的にDenseNetと比較していこうと思う。乞うご期待!
この記事は、METRICAの社内勉強会用の資料を改稿して作りました。
[2019/7/7追記]後編できました。
特徴を段階ごとに分けて生成できるモデル「StyleGAN」を読んでみました
インターンの中村です。
今回はStyleGANを読んだので解説していきます。
https://arxiv.org/abs/1812.04948
NVIDIAの論文です。GPU開発元らしく潤沢なGPU資源を使って超リアルな画像を生成した1ことで話題になりましたが、特徴をレベルごとに分離するGeneratorの構造が独特で内容的にも面白いです。
この記事では、GANの基礎をさらっとさらい、そのあとでStyleGANのアーキテクチャの説明をします。
GANって何
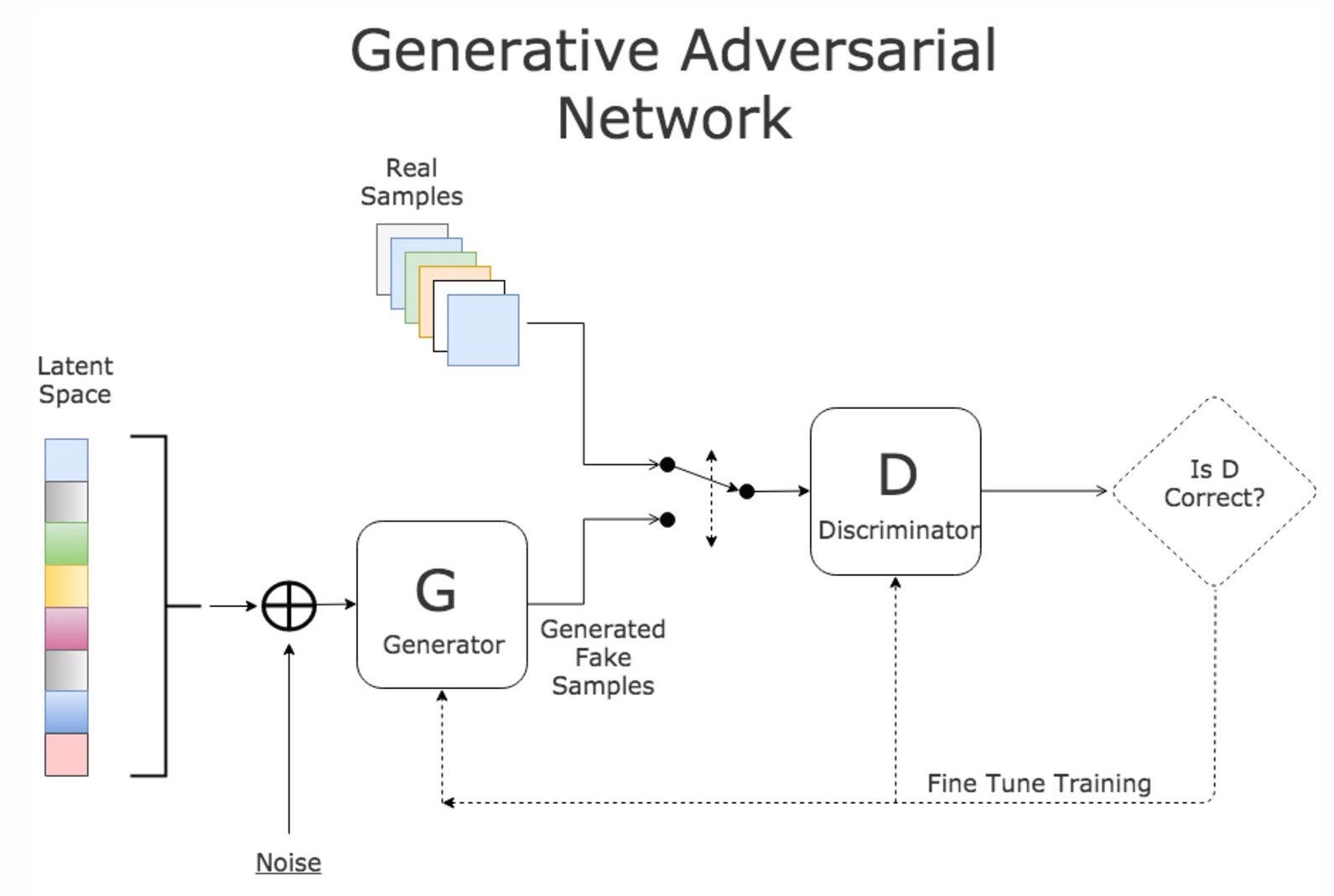
生成モデル(Generator)を敵対モデル(Adversarial Net,「真贋を判定するもの」なのでDiscriminatorとも)と同時に訓練させることで生成されるもの(画像、音声etc...)の質をあげようという試み
$$ \mathcal{L}_{G A N}(G, D)= \mathbb{E}_{y} [ \log D(y) ]+ \mathbb{E}_{z} [\log (1-D(G(z)) ] $$
$G$はこれを小さくしようとし(=$D$を騙そうとし)、敵である$D$は大きくしようとする(見分けようとする)。 損失関数が定義されているので、深層学習モデルを$G$や$D$に使うことも可能(最近は全部そう)。
例題
https://qiita.com/taizan/items/cf77fd37ec3a0bef5d9d
これの$G,D,z,y$は何?
答え
- $G$: 線画から色付き画像を生成するもの
- $D$: 色付き画像が「イラストレーターに作られたもの」か「$G$に塗られたもの」か判定するもの
- $z$: 線画。したがって、$G(z)$が偽物の色付き画像になる
- $y$: イラストレータに作られた、本物の色付き画像
本論文

- Generatorの新たなアーキテクチャを提案
- 最初の層ではなく途中の層に確率的な影響を追加する
- スタイル$A$を追加
- 確率的な影響$B$を追加
- これにより「スタイル(人物の同一性などの大きい特徴)」「確率的な影響(そばかすや髪の位置)」「その大きさ」をネットワークの構造において分離した

緑の箱が学習可能な要素。
- 定数の入力からスタートし、"スタイル”を途中の層にAdainで追加する(左側のA)
- フィルタの出力を正規化したあと、チャンネルごとに異なる1次関数を掛けている
- つまり、いわゆる切片と傾きが箱A(に入ってくる乱数$\mathbf{w}$)で決定される。下の式では$\mathbf{y}$と書かれている
$$ \operatorname{AdaIN} \left( \mathbf{x}_{i} , \mathbf{y} \right) = \mathbf{y}_{s, i} \frac{\mathbf{x}_{i} - \mu \left( \mathbf{x}_{i} \right) }{\sum \left( \mathbf{x}_{i} \right)} + \mathbf{y}_{b, i} $$
さらに定数倍したノイズを追加(右側のB)
この研究では損失、正則化、ハイパラの新規性はなし。Gの構造のみが提案されている
結果

それぞれの変更としては、
C: Adain演算を追加
D: 最初の層の入力を定数に
- これまでのGでは乱数が一般的だったので、これにより性能が上がったのには驚きである
E: ノイズ入力(Bを$\oplus$してるやつ)を追加
F: 時々、異なる層には別の$\mathbf{z}$から生成された$\mathbf{w}$を入力してやった(スタイルミキシングと呼んでいる)
- 別の層に入力されたスタイルに関連性はないんだ、と教えてやる意味を持つ
- ただ、この表の評価からするに効果はあったりなかったり
定性的評価
AdaIN演算

最初の方の層(Coarse: 4x4/8x8)の$A$を取り替えると姿勢、髪型、顔の形、眼鏡といった高レベルな特徴が取り替えられる 真ん中の層だと表情、目の開閉、細かい髪型といった特徴が、 最後の方の層(Fine: 64x64-1024x1024)だと色の雰囲気や微小な要素のみが変わる

モデルFは特に複数のノイズから生成されたLatent Codeを混ぜながら(スタイルミキシングしながら)スコアを取ると点数が良い(→自然な画像が生成されている)
Noise加算

ノイズによって髪が細かく変わっているのがわかる このように、そばかすや髪の流れといった確率的に決まる要素がノイズ加算によって決定されるようだ (c)はノイズによって変化しやすい場所を表した図。頬と髪などをくらべるとわかりやすい

- (a)ノイズあり
- (b)ノイズなし
- 「画家っぽい」感じに
- (c)Fine Layersのみにノイズ
- (d)coarse layersのみにノイズ
ノイズを加える場所によって生成される背景や巻き髪のスケールが違うのがわかる
Latent Codeのdisentanglement

- そもそも、データセットが何らかの領域を欠いている可能性あり(a)
- 例えば、「長い髪の女」「短い髪の女」「短い髪の男」はいるけど「長い髪の男」はいないみたいな
- それを、きれいな形をした$\mathcal{Z}$から生成するように訓練すると空間が曲がる(b)
- $\mathcal{Z}$を無理に訓練データに対応させた結果
- これをlatent codeのentanglementと呼んでいる
- しかし、今回のモデルではFCNによって$\mathcal{W}$に写像してからCNNに入れている
- (c)のほうがリアルな画像を生成しやすいし、俺たちのStyleGANのFCNもこのような$\mathcal{W}$への写像を獲得してんじゃね?(予想)
定量評価
というわけで実際に評価してみた

Path LengthとSeparabilityの2つがある:これらもこの論文で提案された手法である
Path Length
適当に選んだ2つの乱数 $\mathbf{z}_1, \mathbf{z}_2$ を $t\in[ 0,1 ]$ で内分した点を考える。更にそこから微小にずらした点($t+\epsilon$で内分した点)も考える
それらを種にして生成された画像をVGG16モデルにかけ、その中間活性の距離を取る(それが下の式の$d$)
- その平均を取る
$$ l_{\mathcal{Z}}=\mathbb{E}[\frac{1}{\epsilon^{2}} d\left(G\left(\operatorname{slerp}\left(\mathbf{z}_{1}, \mathbf{z}_{2} ; t\right)\right),G\left(\operatorname{slerp}\left(\mathbf{z}_{1}, \mathbf{z}_{2} ; t+\epsilon\right)\right) \right) ] $$
- つまりこう↑
- StyleGANだと$\mathcal{W}$にマップされているので
$$ l_{\mathcal{W}}=\mathbb{E}[\frac{1}{\epsilon^{2}} d\left(g\left(\operatorname{lerp}\left(f\left(\mathbf{z}_{1}\right), f\left(\mathbf{z}_{2}\right) ; t\right)\right),g\left(\operatorname{lerp}\left(f\left(\mathbf{z}_{1}\right), f\left(\mathbf{z}_{2}\right) ; t+\epsilon\right)\right) \right) ] $$
- こう↑なる
- 結果、StyleGANのほうが小さかった
- $t \in\{0,1\}$にする(選んだ2つの点の付近だけで計算する)とさらに小さくなった
- 表中ではendと書かれているところ
- $\mathcal{Z}$に実際には逆像の存在しない$\mathcal{W}$の領域(上の例でいう長い髪の男)について距離を計算することがなくなったためか
この指標にはどのような意味合いがあるのか?
- 当然ある程度の距離は(異なる画像の中間活性なのだから)生まれるものと考えられるが、変化が不自然/激しいと大きくなる
- 例えば、生成画像が大人の男から女に変化する途中で一旦子供になったり、ましてや人間でないものに変化していたりしたら大きくなってしまうだろう
- つまり、これが小さいことは変化が(VGG16にとって≒人間の視覚にとって)「線形」に近いということになる。なので小さい方がentanglementを解消できていることになり嬉しい
Separability
- たくさん(20万サンプルとか)生成する
- 別の分類器で特定の特徴について分類する
- ex.男か女か
- 確信を持って分類されているもの上位10万個を選ぶ
- これらのサンプルを生成したLatent Code$\mathbf{w}$がどのくらい多次元超平面でSeparableなのかを線形SVMで分離して予測する
- エントロピー$\mathrm{H}(Y | X)$を算出
- $X$がSVMの予測
- $Y$が分類機の予測
- 「超平面のどちらに$\mathbf{w}$がいるのかがわかったとき、実際の予測クラスを知るのに必要な追加情報量」に相当する。なので低いほうが良い
40種類の特徴について$\exp \left(\sum_{i=0}^{40} \mathrm{H}\left(Y_{i} | X_{i}\right)\right)$を計算する
StyleGANのほうが強かった
- FCNの深さを上げると、画像の質、Separabilityともに良くなった
- 既存モデルに同じようにFCNを導入すると、$\mathcal{Z}$におけるSeparabilityは大きく低下するものの(10.78→170.29)、$\mathcal{W}$においてはやっぱり下がっている
- 今回のモデル・既存のモデル両方でFCNがentangleを解消する役に立ってる!
感想
スタイル変換の文脈でよく使われていたAdaINをGANに持ち込んだことにより、特徴をレベルごとに独立に生成できるようになったこと、ノイズをFCNによってマップしたうえで$G$に導入することでデータ不均衡によるノイズ空間の歪みを是正する仕組みとしたことが大きなcontributionと言えるでしょう。 脚注にも示したWaifuLabsはStyleGANのこの特性を大いに利用して、インタラクティブにスタイルを選びながら画像を生成できる良質なデモになっているので是非試してみてください。
この記事はMETRICAの内部勉強会用の資料を改稿して作りました
-
https://thispersondoesnotexist.com/ とかhttps://www.thiswaifudoesnotexist.net/ とか。最近だと、StyleGANのカスタマイザビリティをいかしてhttps://waifulabs.com/ こんなのも話題になった。 ↩
MobileNet論文その1: 「MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications」を読みました
この記事は7/6に開催されたMETRICAエンジニア勉強会の発表資料です。
今回は参加者の西本くんがMotibleNetについて発表してくれました。
Mobilenetの特徴
- 軽い
- 速い
- 精度が良い
Depthwise Separable Convolution
Mobile Netの軽量化のための工夫。
わかりやすい動画
https://www.youtube.com/watch?v=T7o3xvJLuHk&feature=youtu.be
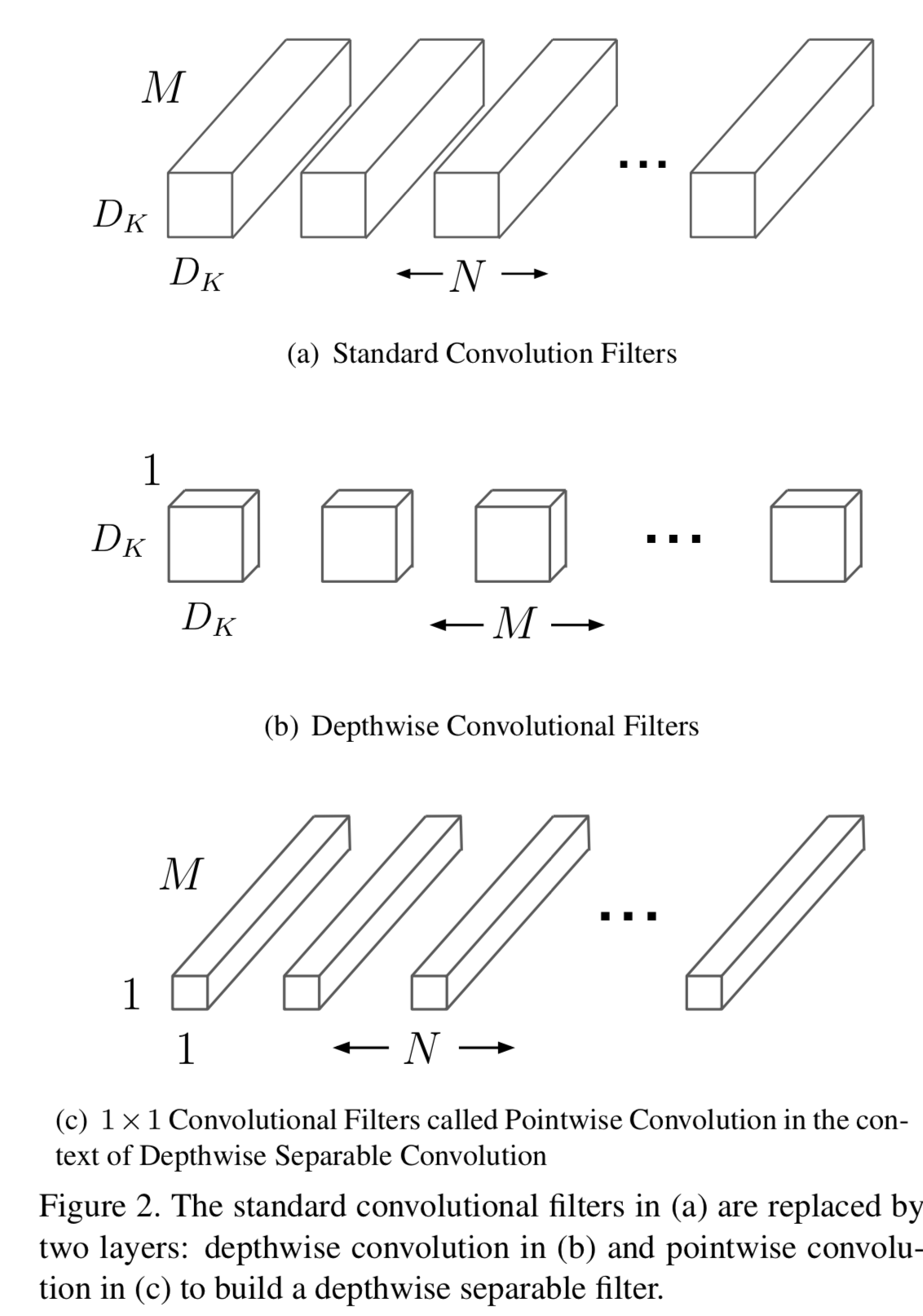
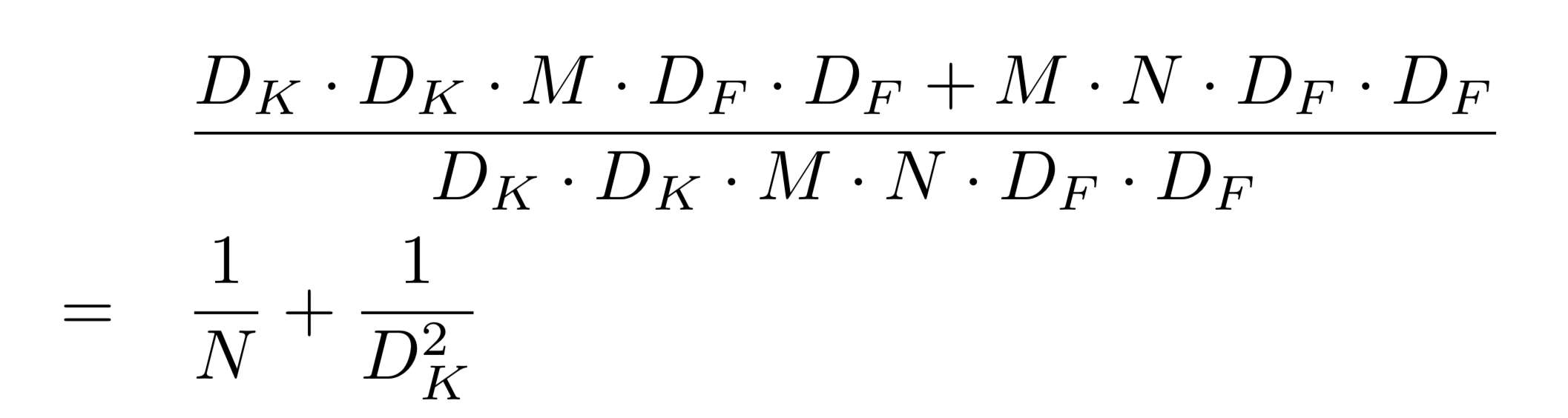
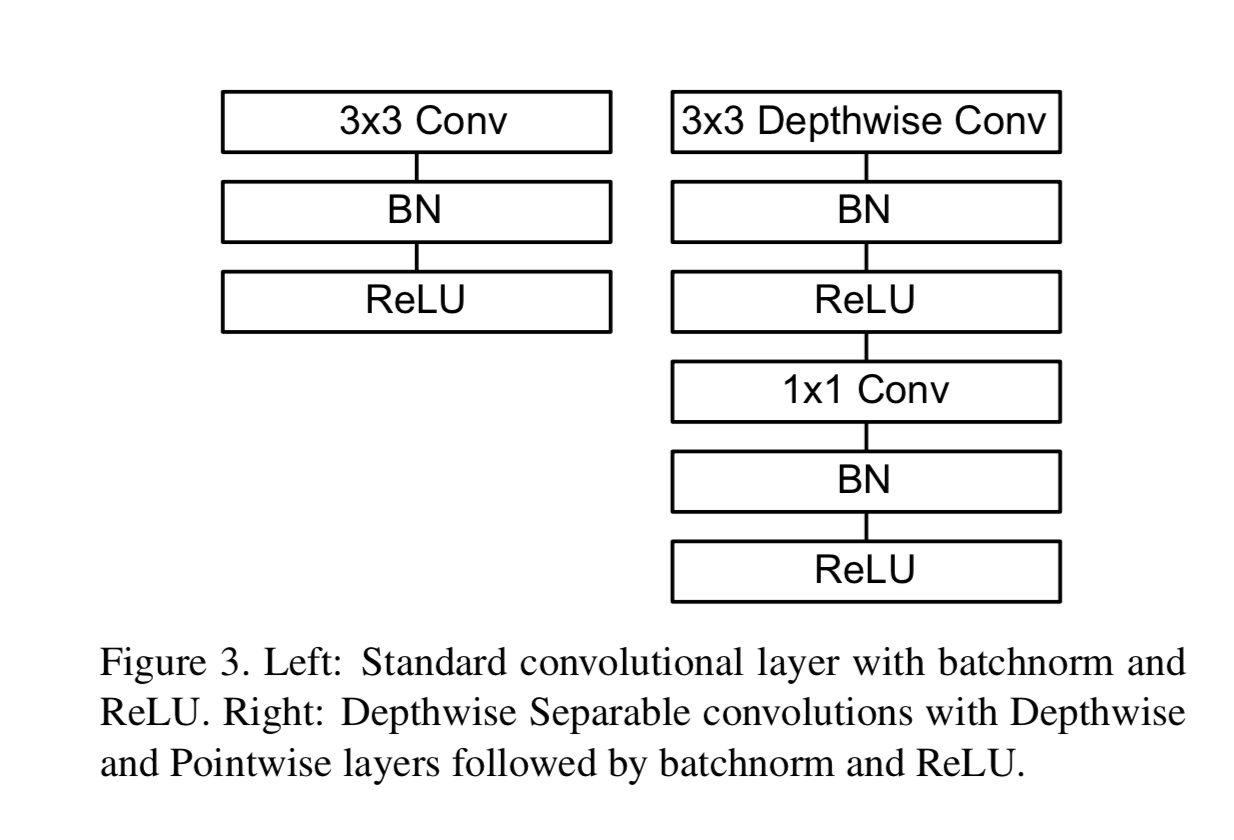
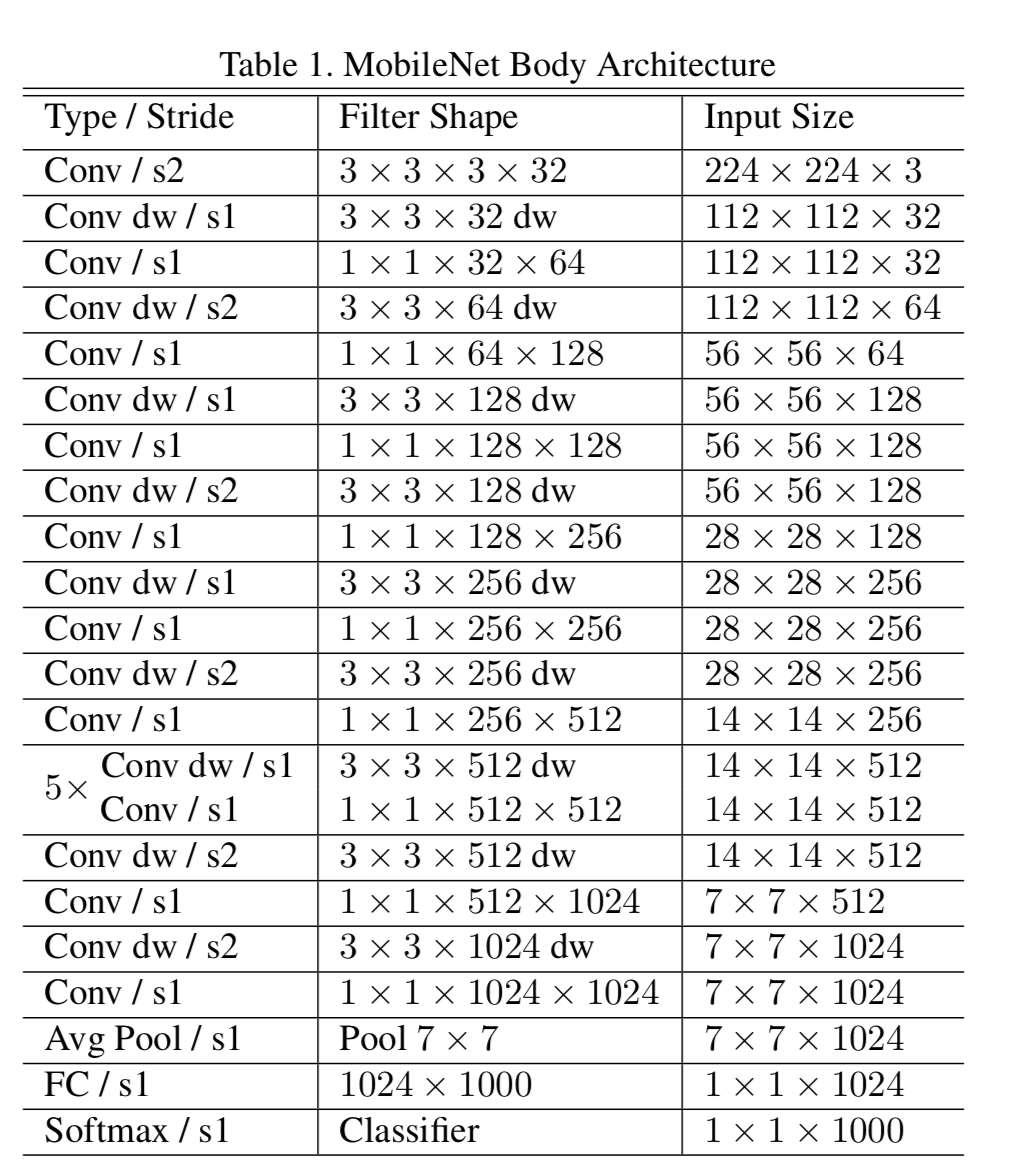
MobileNetの全体の構造
1層目だけFull Convolution層。 2層目以降はdepthwise separable convolutionの繰り返し。
- 積-和演算の数を減らせる
- 残りの積-和計算を効率的に実装できる。
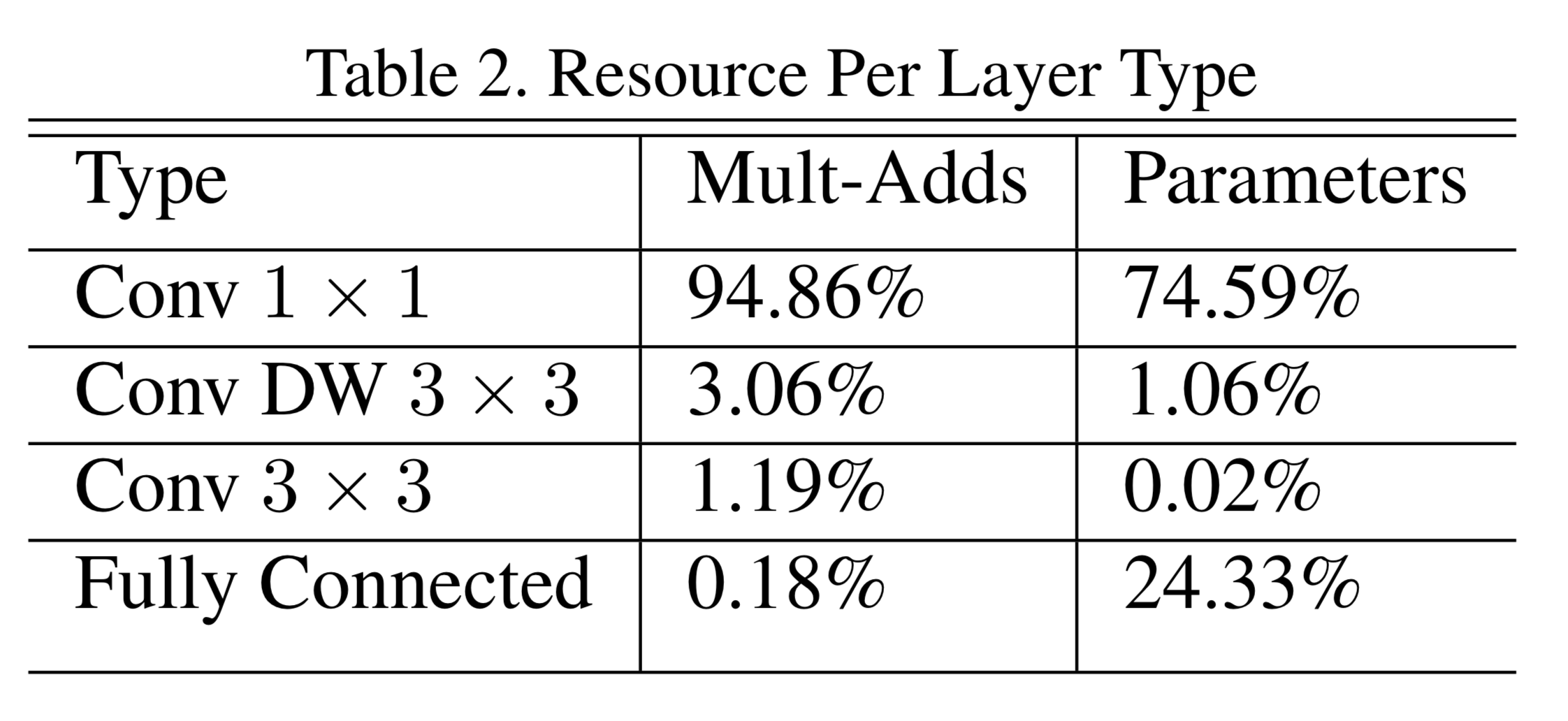
パラメータの75%、計算時間の95%を1x1畳込み層が占めている。
1x1畳込み層は、線形代数の数値計算が最適化されたアルゴリズムの1つであるgeneral matrix multiply (GEMM) functionでdirectに実装可能。
Hyper-parameters
- width multiplier
- 論文では
という記号で表されている。
の範囲で制御可能
- (\alpha)が小さくなるとinput channel, output channelが
倍小さくなる。
- 計算コストは大体
に
- accuracyとのトレードオフがある
- 論文では
- resolution multiplier
- 論文では
という記号で表されている。
の範囲で制御可能
が小さくなるとfeature mapの大きさが
- 計算コストは
倍小さくなる。
- accuracyとのトレードオフがある
- 論文では
ハイパーパラメータを導入すると、Depthwise Separable Convolution の計算にかかるコストは
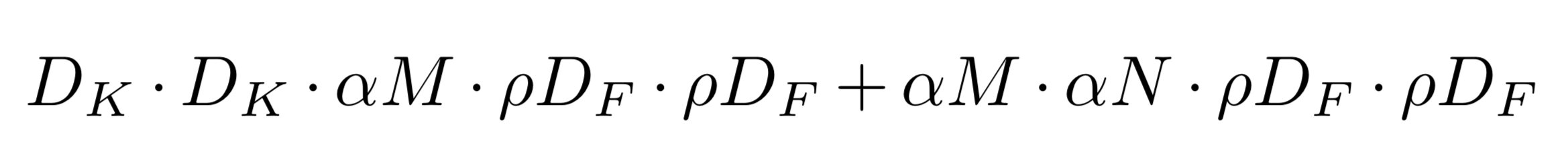
になる。
性能評価
Depthwise Separable vs Full Convolution MobileNet
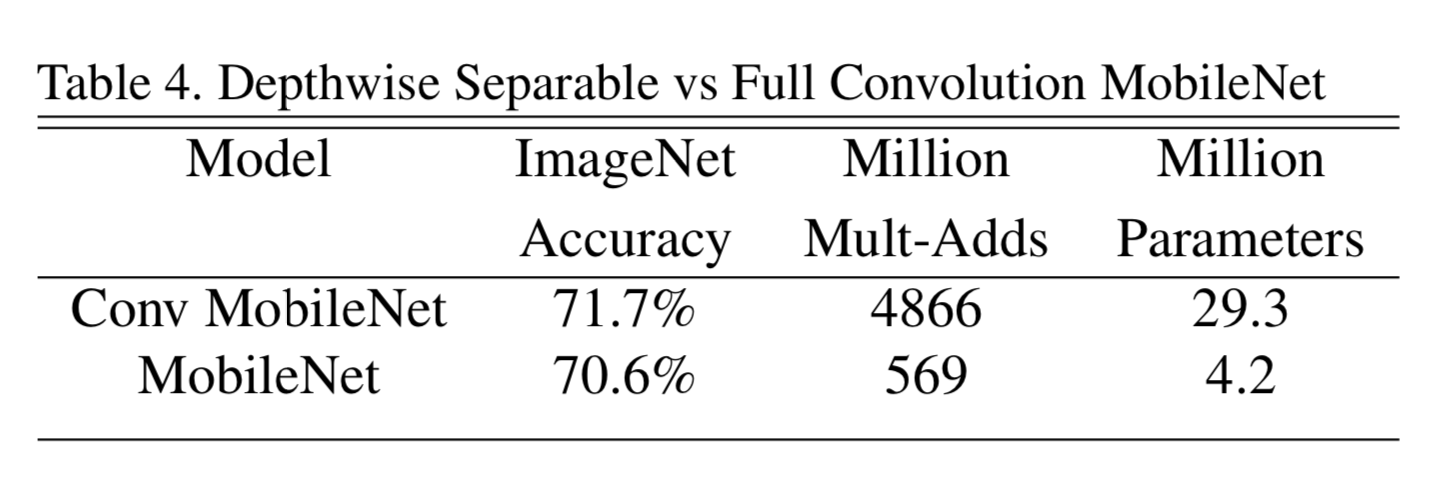
精度はほとんど同じだが、Depthwise Separable の方が積和計算の数、パラメータ数は大幅に少ない。
Narrow vs Shallow MobileNet

MobileNetの層を5層取り除いて浅くしたものと、ハイパーパラメータ(\alpha)を調整して層を薄くしたものの比較。 後者のほうがやや性能良かった。
Model Shrinking Hyperparameters
,
の範囲でハイパーパラメータを変化させたときのモデルの振る舞いを調べた。
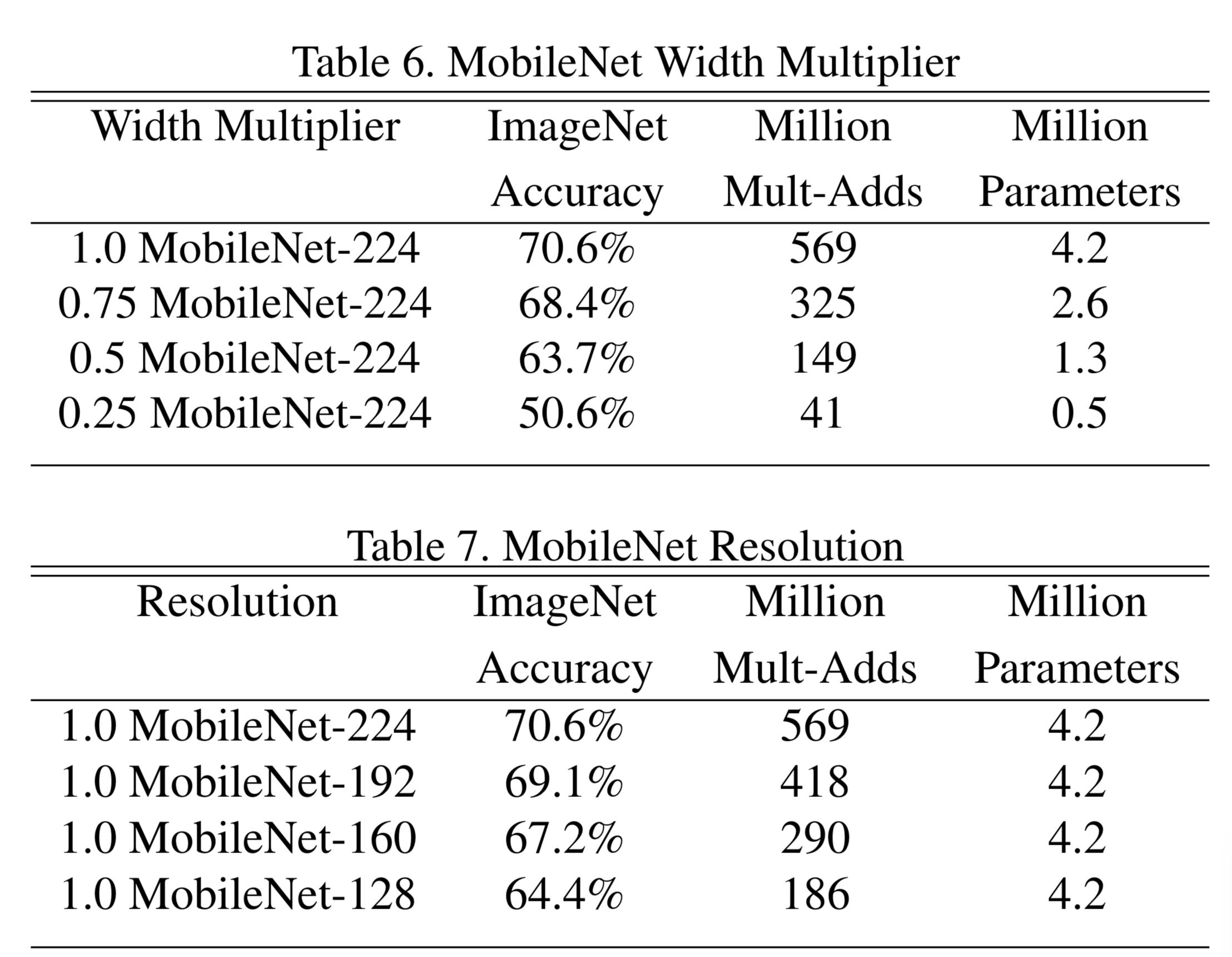
積和計算の数とaccuracyのトレードオフ
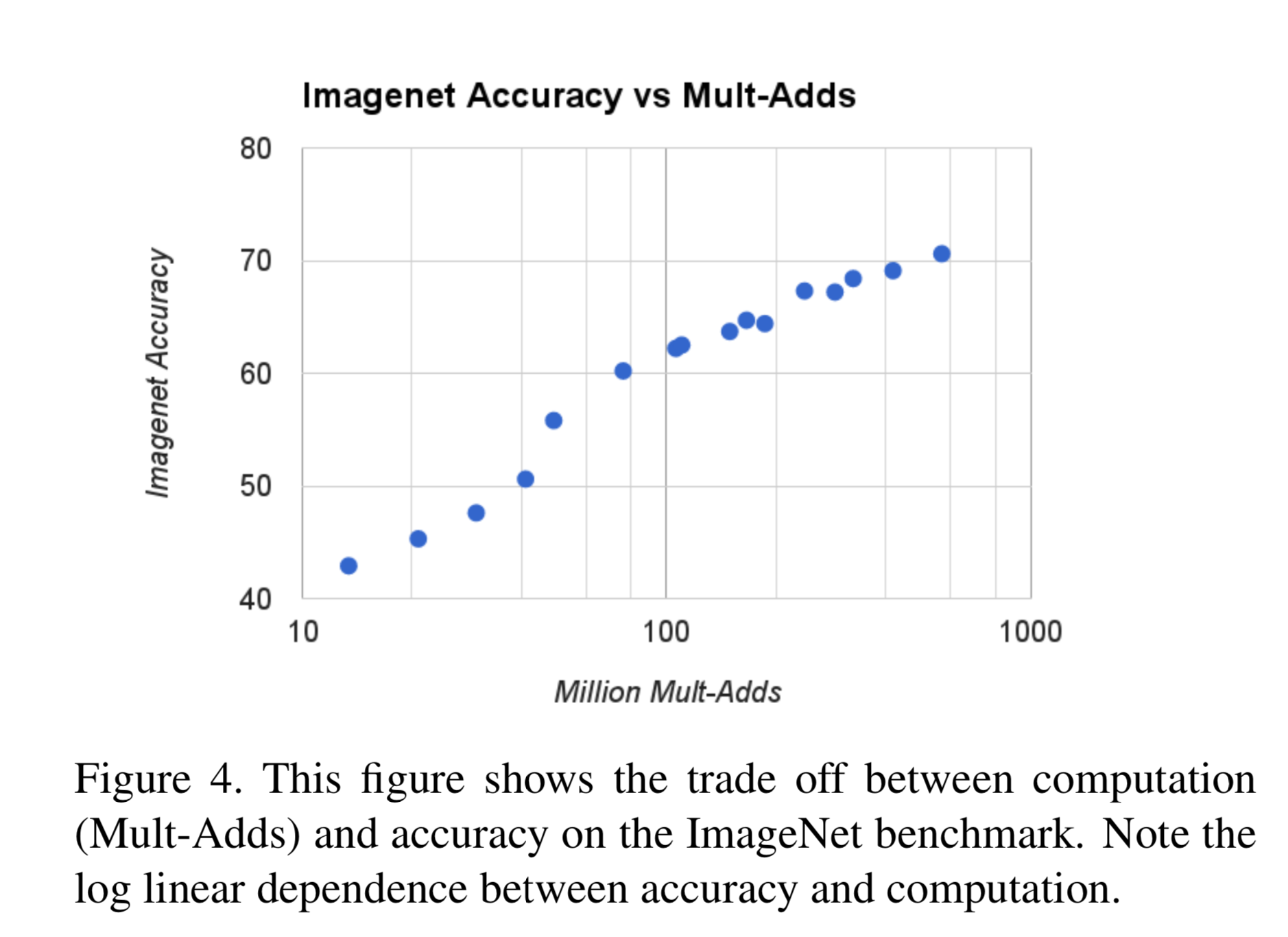
パラメータ数とaccuracyのトレードオフ
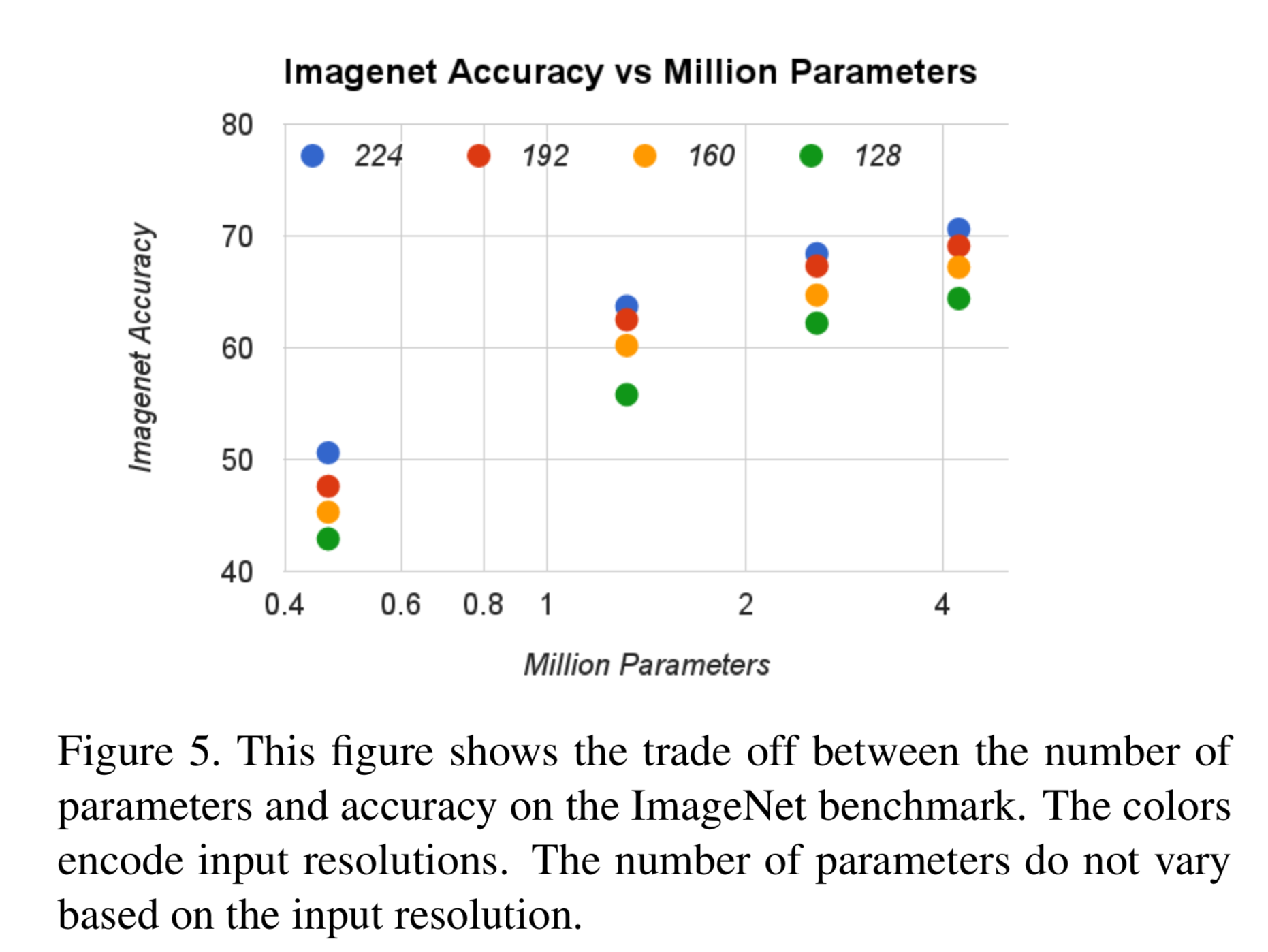
他のモデルとの比較
積和計算、ハイパーパラメータが少ないだけでなく、精度も良い。
様々な場面で応用可能
- PlaNet
- Face attribute classification
- Object classification
参考にした記事
quantization aware trainingの論文「Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference」を読みました
はじめに
CTOの幅野です。
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inferenceを読みました。
この論文はTensorflow/Tensorflow Liteで実装されている、モデルのパラメータを量子化する手法です。
以前まではEdgeTPUで機械学習モデルを推論させるために、この学習方法で行う必要がありましたが、最近のEdgeTPUコンパイラのアップデートによりtensorflowのpost-training quantizationにも対応するようになりました。
post-training quantizationは学習されたモデルに対して、EdgeTPUで推論できるように量子化をする手法です。
なのでquantization aware trainingがEdgeTPUにモデルを載せるために必須ではなくなりましたが、量子化で精度を下げないように学習する手法として今後も利用されると思われます。
Contribution
この論文のContributionは以下の通りです。
- 重みと活性化関数を8bitで表現し、biasを始めとした32bit-integerの少数パラメータを利用したquantization schemeを提案
- 整数演算のみで効率的に計算できるquantized inference framework
- 量子化前のモデルとの精度の誤差を最小限にできるような量子化モデルの推論を設計するquantized training framework
- Classification, detectionタスクにおいてlatency -vs- accuracy tradeoffがMobileNetよりよかった
Quantization Scheme
本論文では量子化された値$q$と実数値$r$の対応関係を表します。 Quantization Schemeは学習時にはfloat,推論時には整数で演算することができます。
Quantization Schemeの基本構造
$$ r=S(q-Z) $$
$r$は量子化前の実数(float)で$q$は量子化後の整数(int)を表します。 $S$は$r$と$q$のスケールを調整する実数(float)です。 $Z$は$r$が0で表現されるように$q$を調整するオフセットとなります。
C++の構造体として表現すると以下のようになります。

Quantization Schemeを利用した計算
ではQuantization Schemeを利用した計算を考えてみましょう。 $N \times N$の行列$r_1$と$r_2$あった時に$r_3 = r_1 * r_2$を計算することを考えます。 $r_1$と$r_2$は実際のニューラルネットワークでは伝搬されてきた入力値と重みに対応していています。 $r_{\alpha}$の定義は以下のようになります。
$$r_{\alpha}^{(i, j)}=S_{\alpha}\left(q_{\alpha}^{(i, j)}-Z_{\alpha}\right)$$
これを元に$r_3$を展開します。 $$S_{3}\left(q_{3}^{(i, k)}-Z_{3}\right)=\sum_{j=1}^{N} S_{1}\left(q_{1}^{(i, j)}-Z_{1}\right) S_{2}\left(q_{2}^{(j, k)}-Z_{2}\right)$$ ここで、$S$は入力の値に影響しない定数であることから推論前にオフラインで $M$ を計算することができます。 $$q_{3}^{(i, k)}=Z_{3}+M \sum_{j=1}^{N}\left(q_{1}^{(i, j)}-Z_{1}\right)\left(q_{2}^{(j, k)}-Z_{2}\right)$$
$$M :=\frac{S_{1} S_{2}}{S_{3}}$$
しかし、$S$はfloatであり、推論時には$M$を整数演算として計算したいです。 $M$は試験的に計算をすると$[0,1]$の範囲となることがわかったそうです。 なので$M_0$を導入して整数演算で計算できるようにします。 $$M=2^{-n} M_{0}$$ $n$は非負の値で$M_0$は本来$[0,0.5)$ではあるが整数演算を行うためにビットシフトさせた値である。 $M$をint32と考えると$M_0 = 2^{31} M_0$と整数に変換しこの時$M_0$は少なくとも$2^{30}$の情報量を格納することができます。このように$M_0$を変換させて計算をすることにより、$M$を整数演算として考えることができます。
ここからさらに$\sum_{j=1}^{N}\left(q_{1}^{(i, j)}-Z_{1}\right)\left(q_{2}^{(j, k)}-Z_{2}\right)$を展開してみます。
$$q_{3}^{(i, k)}=Z_{3}+M\left(N Z_{1} Z_{2}-Z_{1} a_{2}^{(k)}\right.-Z_{2} a_{1}^{(i)}+\sum_{j=1}^{N} q_{1}^{(i, j)} q_{2}^{(j, k)} )$$
$$a_{2}^{(k)} :=\sum_{j=1}^{N} q_{2}^{(j, k)},a_{1}^{(i)} :=\sum_{j=1}^{N} q_{1}^{(i, j)}$$ ここで$a_{2}^{(k)}$と$a_{1}^{(i)}$はそれぞれ$N$回加算をすることで演算ができます。なのでこれらの加算回数は一つの行列積として合計$2N^2$回加算で計算することが可能なわけです。
$\sum_{j=1}^{N} q_{1}^{(i, j)} q_{2}^{(j, k)}$は整数行列の積和演算に該当する部分なので$2N^3$回積和演算が呼ばれます。しかしこの項を除いた演算は$O(N^2)$で計算をすることができます。
Quantization Schemeを利用した推論
Quantization Schemeを利用したモデルはFigure1.1の左のように計算されます。
 ここでバイアス項が32bitになっていますが、著者らは以下の部分を考慮して32bitにしています。
ここでバイアス項が32bitになっていますが、著者らは以下の部分を考慮して32bitにしています。
しかしバイアスを足した値は$M$もint32であることから32ビットになってしまい、次の活性化関数や層の計算を8bitでは行えないためここで8bitへcast downしています。
Quantized Training Framework
量子化を考慮した学習方法
これまでの量子化方法は学習したモデルのパラメータの値を量子化していました。しかし、これらの方法には2つ欠点があると主張しています。
- 出力チャネルごとの重みの幅に大きな差がでてしまう
- 外れ値に強く影響しやすくなる
なので精度を維持する量子化をするために学習時にQuantized Training Frameworkを利用します。 Quantized Training Frameworkによる学習の流れは以下のとおりです。

- 重み、バイアスをFake QuantizationしてFoward
- 重み、バイアスはfloatを保持してBackpropagation
- 更新した重み、バイアス(float)をFake QuantizationしてFoward
Fake Quantization
Fake QuantizationはfloatのパラメータをFoward時に量子化する手法です。 Fake QuantizationはQuantization Schemeで計算される値を丸める計算を浮動小数点演算で計算しています。

評価
Imagenet Classification, COCO Object Detectionなど様々なタスクで評価しています。
Imagenet
量子化による精度の比較
ResNetにおけるFloating pointのモデルと量子化されたモデルの精度比較です。
精度としては2%ほど差があります。

量子化手法の精度比較
先行研究の量子化手法との精度比較です。
本手法が一番高い結果となっています。

活性化関数の量子化による精度比較
InceptionV3モデルの活性化関数を量子化したことによる精度比較です。 7bitと8bitを比較するとほとんど精度として差がでていない結果となっています。

Mobile Netsの量子化
Mobile Netsを量子化したときのLatencyとTop1Accuracyの精度比較です。 Depth Multiplier(DM)を変動させたことによるLatency, Top1Accuracyの結果をマッピングした図です。


Floatと比較するとAccucacy vs Latencyのトレードオフは良くなっている気がします。 またQualcomm Snapdragonはそもそも浮動小数点演算に最適化されているらしく、あまりLatencyに差が出ないということを主張しているので、他のハードだと更に差が出る可能性があります。
Quantization aware training vs after training
Tensorflow技術ブログではQuantization aware trainingと学習した後のモデルに対して量子化を行うQuantization after trainingで精度比較を行っています。
データセットはimagenetです。
 引用:https://miro.medium.com/max/1400/1*jKJdkOme2Z4lFkcG0UEUQg.png
引用:https://miro.medium.com/max/1400/1*jKJdkOme2Z4lFkcG0UEUQg.png
モデルはよりますが、Quantization aware trainigのほうがafter trainingと比べると精度は若干高いことがわかりますがそれほど差が出てないと感じます。また同記事では今後もQuantization aware trainingのAPIは開発していくと主張しており、それまではpost-training quantizationを推奨しています。
参考文献
TensorFlow Model Optimization Toolkit — Post-Training Integer Quantization
Deep Learning推論用デバイスその3 Google Edge TPU
はじめに
この記事はDeepLearning推論用デバイスまとめ記事の第三弾です。第三弾ではGoogleが提供しているEdge TPUについて紹介します。他のデバイスに関しては下記にまとめています。
Google Edge TPU
TPUとは
Tensor Processing Unit(TPU)はGoogleが開発したプロセッサです。TPUは機械学習の計算を高速化するために設計されたASICで、Google翻訳やGoogle検索などのクラウドサービスでもCloud TPUとして利用されておりました。他社のアクセラレータ(NVIDIAなど)とTPUのパフォーマンス検証についてはGoogleの技術ブログにて公開されています。
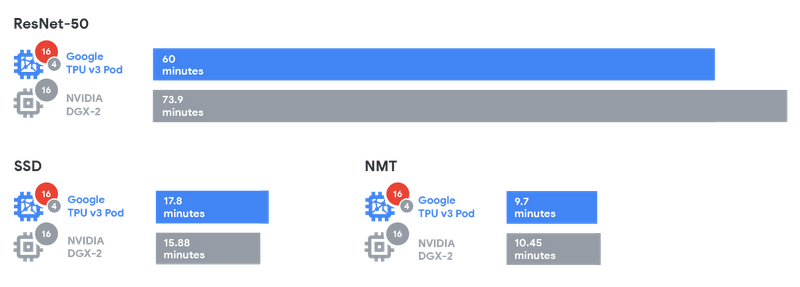
(引用:https://storage.googleapis.com/gweb-cloudblog-publish/images/Graphic2_2x.max-800x800.png)
上記の表を見るとSSD以外の2つのモデルに対しては学習時間が短くなっています。
Edge TPU
Cloud TPUはGoogleのクラウドサービスやGCPでのモデル学習などに利用されています。それに対してTPUを推論に利用するために開発されたのがEdge TPUです。Edge TPUは開発ボードとUSB型アクセラレータの2つが提供されています。
Dev Board

){kind=link}
| CPU | NXP i.MX 8M SoC (quad Cortex-A53, Cortex-M4F) |
|---|---|
| GPU | Integrated GC7000 Lite Graphics |
| ML accelerator | Google Edge TPU coprocessor |
| RAM | 1 GB LPDDR4 |
| Flash memory | 8 GB eMMC |
| Wireless | Wi-Fi 2x2 MIMO (802.11b/g/n/ac 2.4/5GHz) and Bluetooth 4.2 |
| Dimensions | 48mm x 40mm x 5mm |
(引用:https://coral.withgoogle.com/products/dev-board)
USB Accelerator
USB AcceleratorはDev BoardからAcceleratorを分離してUSBとして提供したものです。これにより、Accelerator以外のマシンをカスタマイズできるようになっています。ホストマシンはLinux OSである必要があります。
推論速度
Googleの技術ブログより公開されている推論速度の比較です。TPU Edgeを利用したときと利用していない時で比較を行っています。モデルはImagenetを学習させたモデルです。
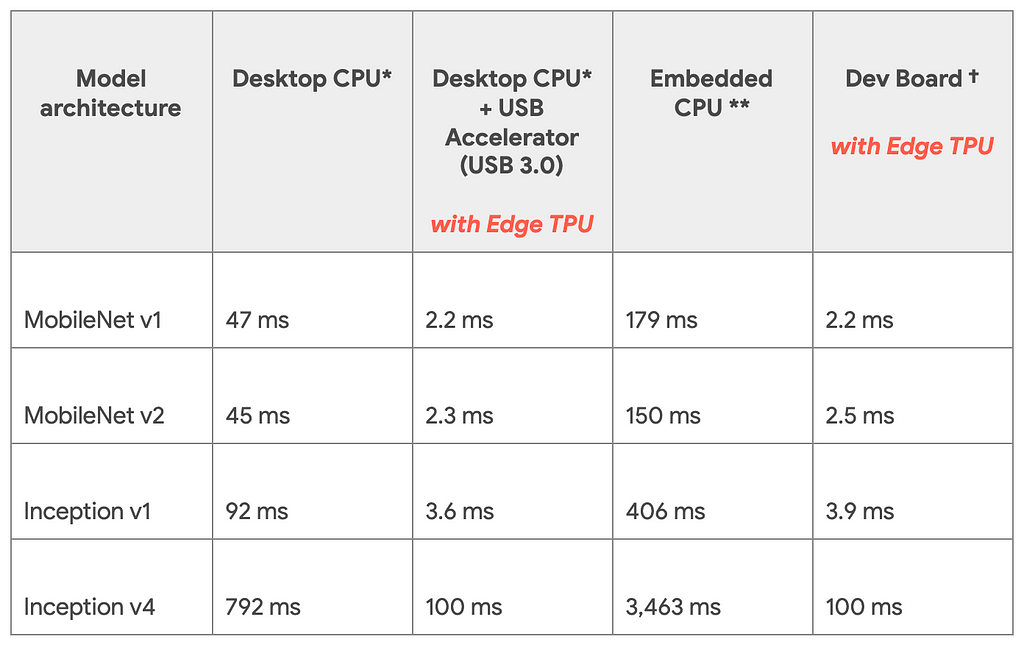 (引用:https://cdn-images-1.medium.com/max/1024/1*pCYQHA_PmF2_awq2coMJvg.png)
(引用:https://cdn-images-1.medium.com/max/1024/1*pCYQHA_PmF2_awq2coMJvg.png)
Dev BoardとUSB Acceleratorで推論速度が変わっていないことからCPU自体のスペックにはほとんど影響しないということがこの表からわかります。 また同じハードでモデル同士を比較するとDesktop CPUにおけるInception v4からMobile Net V1は16倍速くなっているといえますが、Dev Boardの場合だと45倍速くなっていると計算できます。ここを見るとモデルアーキテクチャの違いも速度に影響すると考えられます。
対応環境
前回のNVIDIA Jetson Nanoの記事でも紹介した通り、Edge TPUを利用して実行するためにはいくつか条件がありますので紹介します。
量子化
モデルの重みは32bitで利用されますが、Edge TPUでは8bit integerに量子化をする必要があります。こちらは学習後の重みを量子化するのではなく学習の段階からQuantization Aware Trainingという手法を利用して学習する必要があります。
テンソルのサイズが定数
Edge TPUで推論する時にはモデル内で利用するテンソルのサイズは定数である必要があります。なので入力サイズの変わるRNN系統のモデルは利用できないです。 こちらにサポートされている演算が載っています。
モデルパラメータがコンパイル時に定数
重み・バイアスは定数である必要があります。なので学習などは想定しておりません。また、VAEで利用されるReparametrization Trickのような乱数を利用した演算はこちらの条件にあってないので推論させることはできなさそうですが、今後検証する必要があります。